Nan Che , Jiang Liu , Fei Yu , Lechao Cheng , Yuxuan Wang , Yuehua Li , Chenrui Liu
{"title":"Multimodality-guided Visual-Caption Semantic Enhancement","authors":"Nan Che , Jiang Liu , Fei Yu , Lechao Cheng , Yuxuan Wang , Yuehua Li , Chenrui Liu","doi":"10.1016/j.cviu.2024.104139","DOIUrl":null,"url":null,"abstract":"<div><div>Video captions generated with single modality, e.g. video clips, often suffer from insufficient event discovery and inadequate scene description. Therefore, this paper aims to improve the quality of captions by addressing these issues through the integration of multi-modal information. Specifically, We first construct a multi-modal dataset and introduce the triplet annotations of video, audio and text, fostering a comprehensive exploration about the associations between different modalities. Build upon this, We propose to explore the collaborative perception of audio and visual concepts to mitigate inaccuracies and incompleteness in captions in vision-based benchmarks by incorporating audio-visual perception priors. To achieve this, we extract effective semantic features from visual and auditory modalities, bridge the semantic gap between audio-visual modalities and text, and form a more precise knowledge graph multimodal coherence checking and information pruning mechanism. Exhaustive experiments demonstrate that the proposed approach surpasses existing methods and generalizes well with the assistance of ChatGPT.</div></div>","PeriodicalId":50633,"journal":{"name":"Computer Vision and Image Understanding","volume":"249 ","pages":"Article 104139"},"PeriodicalIF":3.5000,"publicationDate":"2024-12-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computer Vision and Image Understanding","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1077314224002200","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/9/23 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
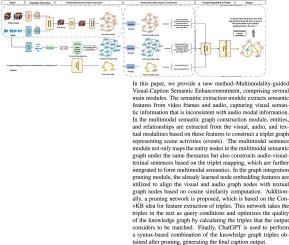
Video captions generated with single modality, e.g. video clips, often suffer from insufficient event discovery and inadequate scene description. Therefore, this paper aims to improve the quality of captions by addressing these issues through the integration of multi-modal information. Specifically, We first construct a multi-modal dataset and introduce the triplet annotations of video, audio and text, fostering a comprehensive exploration about the associations between different modalities. Build upon this, We propose to explore the collaborative perception of audio and visual concepts to mitigate inaccuracies and incompleteness in captions in vision-based benchmarks by incorporating audio-visual perception priors. To achieve this, we extract effective semantic features from visual and auditory modalities, bridge the semantic gap between audio-visual modalities and text, and form a more precise knowledge graph multimodal coherence checking and information pruning mechanism. Exhaustive experiments demonstrate that the proposed approach surpasses existing methods and generalizes well with the assistance of ChatGPT.
期刊介绍:
The central focus of this journal is the computer analysis of pictorial information. Computer Vision and Image Understanding publishes papers covering all aspects of image analysis from the low-level, iconic processes of early vision to the high-level, symbolic processes of recognition and interpretation. A wide range of topics in the image understanding area is covered, including papers offering insights that differ from predominant views.
Research Areas Include:
• Theory
• Early vision
• Data structures and representations
• Shape
• Range
• Motion
• Matching and recognition
• Architecture and languages
• Vision systems




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
