{"title":"基于输入数据的乳腺癌复发分类:模拟研究。","authors":"Rahibu A Abassi, Amina S Msengwa","doi":"10.1186/s13040-022-00316-8","DOIUrl":null,"url":null,"abstract":"<p><p>Several studies have been conducted to classify various real life events but few are in medical fields; particularly about breast recurrence under statistical techniques. To our knowledge, there is no reported comparison of statistical classification accuracy and classifiers' discriminative ability on breast cancer recurrence in presence of imputed missing data. Therefore, this article aims to fill this analysis gap by comparing the performance of binary classifiers (logistic regression, linear and quadratic discriminant analysis) using several datasets resulted from imputation process using various simulation conditions. Our study aids the knowledge about how classifiers' accuracy and discriminative ability in classifying a binary outcome variable are affected by the presence of imputed numerical missing data. We simulated incomplete datasets with 15, 30, 45 and 60% of missingness under Missing At Random (MAR) and Missing Completely At Random (MCAR) mechanisms. Mean imputation, hot deck, k-nearest neighbour, multiple imputations via chained equation, expected-maximisation, and predictive mean matching were used to impute incomplete datasets. For each classifier, correct classification accuracy and area under the Receiver Operating Characteristic (ROC) curves under MAR and MCAR mechanisms were compared. The linear discriminant classifier attained the highest classification accuracy (73.9%) based on mean-imputed data at 45% of missing data under MCAR mechanism. As a classifier, the logistic regression based on predictive mean matching imputed-data yields the greatest areas under ROC curves (0.6418) at 30% missingness while k-nearest neighbour tops the value (0.6428) at 60% of missing data under MCAR mechanism.</p>","PeriodicalId":48947,"journal":{"name":"Biodata Mining","volume":"15 1","pages":"30"},"PeriodicalIF":7.9000,"publicationDate":"2022-12-07","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9727846/pdf/","citationCount":"0","resultStr":"{\"title\":\"Classification of breast cancer recurrence based on imputed data: a simulation study.\",\"authors\":\"Rahibu A Abassi, Amina S Msengwa\",\"doi\":\"10.1186/s13040-022-00316-8\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Several studies have been conducted to classify various real life events but few are in medical fields; particularly about breast recurrence under statistical techniques. To our knowledge, there is no reported comparison of statistical classification accuracy and classifiers' discriminative ability on breast cancer recurrence in presence of imputed missing data. Therefore, this article aims to fill this analysis gap by comparing the performance of binary classifiers (logistic regression, linear and quadratic discriminant analysis) using several datasets resulted from imputation process using various simulation conditions. Our study aids the knowledge about how classifiers' accuracy and discriminative ability in classifying a binary outcome variable are affected by the presence of imputed numerical missing data. We simulated incomplete datasets with 15, 30, 45 and 60% of missingness under Missing At Random (MAR) and Missing Completely At Random (MCAR) mechanisms. Mean imputation, hot deck, k-nearest neighbour, multiple imputations via chained equation, expected-maximisation, and predictive mean matching were used to impute incomplete datasets. For each classifier, correct classification accuracy and area under the Receiver Operating Characteristic (ROC) curves under MAR and MCAR mechanisms were compared. The linear discriminant classifier attained the highest classification accuracy (73.9%) based on mean-imputed data at 45% of missing data under MCAR mechanism. As a classifier, the logistic regression based on predictive mean matching imputed-data yields the greatest areas under ROC curves (0.6418) at 30% missingness while k-nearest neighbour tops the value (0.6428) at 60% of missing data under MCAR mechanism.</p>\",\"PeriodicalId\":48947,\"journal\":{\"name\":\"Biodata Mining\",\"volume\":\"15 1\",\"pages\":\"30\"},\"PeriodicalIF\":7.9000,\"publicationDate\":\"2022-12-07\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9727846/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Biodata Mining\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1186/s13040-022-00316-8\",\"RegionNum\":3,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biodata Mining","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13040-022-00316-8","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
Classification of breast cancer recurrence based on imputed data: a simulation study.
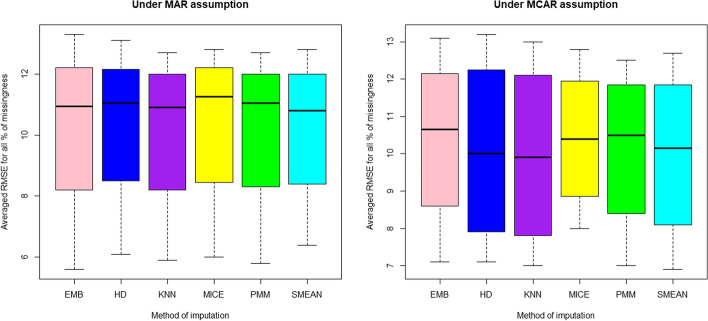
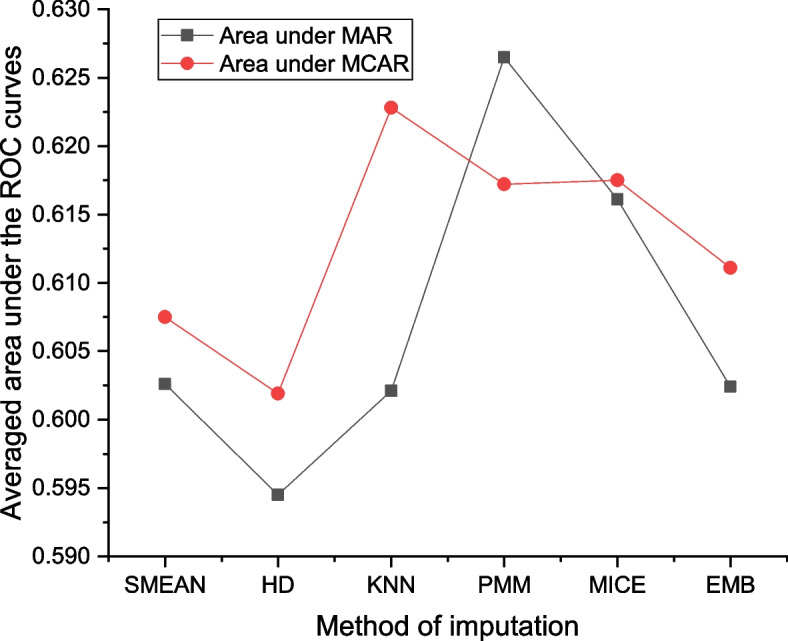
Several studies have been conducted to classify various real life events but few are in medical fields; particularly about breast recurrence under statistical techniques. To our knowledge, there is no reported comparison of statistical classification accuracy and classifiers' discriminative ability on breast cancer recurrence in presence of imputed missing data. Therefore, this article aims to fill this analysis gap by comparing the performance of binary classifiers (logistic regression, linear and quadratic discriminant analysis) using several datasets resulted from imputation process using various simulation conditions. Our study aids the knowledge about how classifiers' accuracy and discriminative ability in classifying a binary outcome variable are affected by the presence of imputed numerical missing data. We simulated incomplete datasets with 15, 30, 45 and 60% of missingness under Missing At Random (MAR) and Missing Completely At Random (MCAR) mechanisms. Mean imputation, hot deck, k-nearest neighbour, multiple imputations via chained equation, expected-maximisation, and predictive mean matching were used to impute incomplete datasets. For each classifier, correct classification accuracy and area under the Receiver Operating Characteristic (ROC) curves under MAR and MCAR mechanisms were compared. The linear discriminant classifier attained the highest classification accuracy (73.9%) based on mean-imputed data at 45% of missing data under MCAR mechanism. As a classifier, the logistic regression based on predictive mean matching imputed-data yields the greatest areas under ROC curves (0.6418) at 30% missingness while k-nearest neighbour tops the value (0.6428) at 60% of missing data under MCAR mechanism.
期刊介绍:
BioData Mining is an open access, open peer-reviewed journal encompassing research on all aspects of data mining applied to high-dimensional biological and biomedical data, focusing on computational aspects of knowledge discovery from large-scale genetic, transcriptomic, genomic, proteomic, and metabolomic data.
Topical areas include, but are not limited to:
-Development, evaluation, and application of novel data mining and machine learning algorithms.
-Adaptation, evaluation, and application of traditional data mining and machine learning algorithms.
-Open-source software for the application of data mining and machine learning algorithms.
-Design, development and integration of databases, software and web services for the storage, management, retrieval, and analysis of data from large scale studies.
-Pre-processing, post-processing, modeling, and interpretation of data mining and machine learning results for biological interpretation and knowledge discovery.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
