{"title":"利用基于熵的核密度估计鉴定基因与数量性状之间的关联。","authors":"Jaeyong Yee, Taesung Park, Mira Park","doi":"10.5808/gi.22033","DOIUrl":null,"url":null,"abstract":"<p><p>Genetic associations have been quantified using a number of statistical measures. Entropy-based mutual information may be one of the more direct ways of estimating the association, in the sense that it does not depend on the parametrization. For this purpose, both the entropy and conditional entropy of the phenotype distribution should be obtained. Quantitative traits, however, do not usually allow an exact evaluation of entropy. The estimation of entropy needs a probability density function, which can be approximated by kernel density estimation. We have investigated the proper sequence of procedures for combining the kernel density estimation and entropy estimation with a probability density function in order to calculate mutual information. Genotypes and their interactions were constructed to set the conditions for conditional entropy. Extensive simulation data created using three types of generating functions were analyzed using two different kernels as well as two types of multifactor dimensionality reduction and another probability density approximation method called m-spacing. The statistical power in terms of correct detection rates was compared. Using kernels was found to be most useful when the trait distributions were more complex than simple normal or gamma distributions. A full-scale genomic dataset was explored to identify associations using the 2-h oral glucose tolerance test results and γ-glutamyl transpeptidase levels as phenotypes. Clearly distinguishable single-nucleotide polymorphisms (SNPs) and interacting SNP pairs associated with these phenotypes were found and listed with empirical p-values.</p>","PeriodicalId":36591,"journal":{"name":"Genomics and Informatics","volume":"20 2","pages":"e17"},"PeriodicalIF":0.0000,"publicationDate":"2022-06-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9299569/pdf/","citationCount":"0","resultStr":"{\"title\":\"Identification of the associations between genes and quantitative traits using entropy-based kernel density estimation.\",\"authors\":\"Jaeyong Yee, Taesung Park, Mira Park\",\"doi\":\"10.5808/gi.22033\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Genetic associations have been quantified using a number of statistical measures. Entropy-based mutual information may be one of the more direct ways of estimating the association, in the sense that it does not depend on the parametrization. For this purpose, both the entropy and conditional entropy of the phenotype distribution should be obtained. Quantitative traits, however, do not usually allow an exact evaluation of entropy. The estimation of entropy needs a probability density function, which can be approximated by kernel density estimation. We have investigated the proper sequence of procedures for combining the kernel density estimation and entropy estimation with a probability density function in order to calculate mutual information. Genotypes and their interactions were constructed to set the conditions for conditional entropy. Extensive simulation data created using three types of generating functions were analyzed using two different kernels as well as two types of multifactor dimensionality reduction and another probability density approximation method called m-spacing. The statistical power in terms of correct detection rates was compared. Using kernels was found to be most useful when the trait distributions were more complex than simple normal or gamma distributions. A full-scale genomic dataset was explored to identify associations using the 2-h oral glucose tolerance test results and γ-glutamyl transpeptidase levels as phenotypes. Clearly distinguishable single-nucleotide polymorphisms (SNPs) and interacting SNP pairs associated with these phenotypes were found and listed with empirical p-values.</p>\",\"PeriodicalId\":36591,\"journal\":{\"name\":\"Genomics and Informatics\",\"volume\":\"20 2\",\"pages\":\"e17\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2022-06-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9299569/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Genomics and Informatics\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.5808/gi.22033\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2022/6/30 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"Agricultural and Biological Sciences\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Genomics and Informatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.5808/gi.22033","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2022/6/30 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"Agricultural and Biological Sciences","Score":null,"Total":0}
Identification of the associations between genes and quantitative traits using entropy-based kernel density estimation.
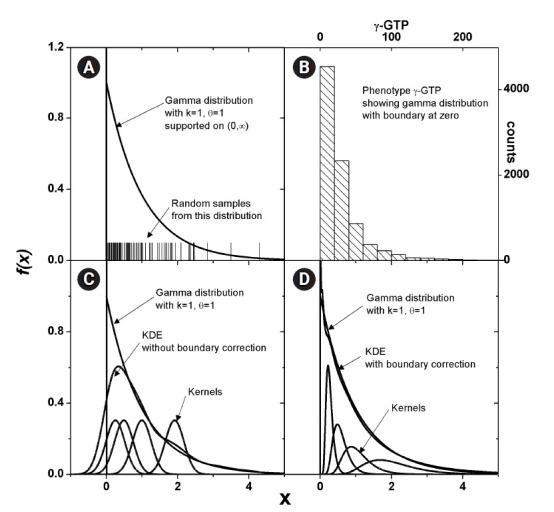
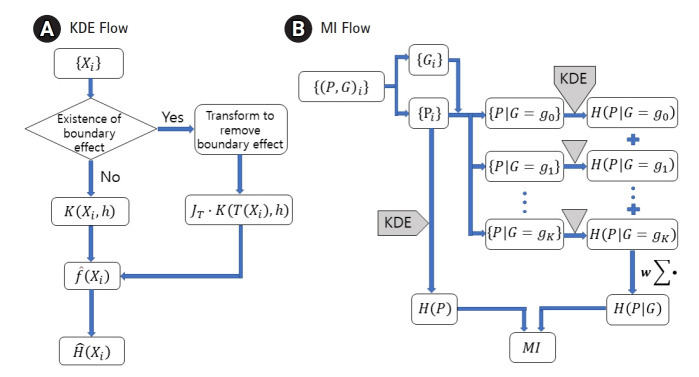
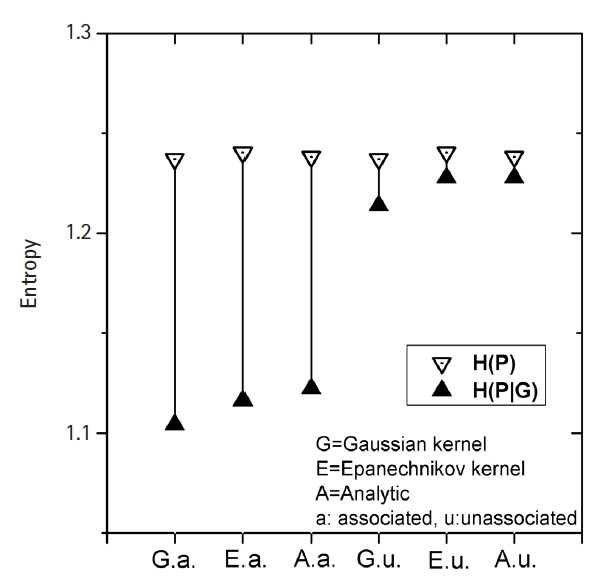
Genetic associations have been quantified using a number of statistical measures. Entropy-based mutual information may be one of the more direct ways of estimating the association, in the sense that it does not depend on the parametrization. For this purpose, both the entropy and conditional entropy of the phenotype distribution should be obtained. Quantitative traits, however, do not usually allow an exact evaluation of entropy. The estimation of entropy needs a probability density function, which can be approximated by kernel density estimation. We have investigated the proper sequence of procedures for combining the kernel density estimation and entropy estimation with a probability density function in order to calculate mutual information. Genotypes and their interactions were constructed to set the conditions for conditional entropy. Extensive simulation data created using three types of generating functions were analyzed using two different kernels as well as two types of multifactor dimensionality reduction and another probability density approximation method called m-spacing. The statistical power in terms of correct detection rates was compared. Using kernels was found to be most useful when the trait distributions were more complex than simple normal or gamma distributions. A full-scale genomic dataset was explored to identify associations using the 2-h oral glucose tolerance test results and γ-glutamyl transpeptidase levels as phenotypes. Clearly distinguishable single-nucleotide polymorphisms (SNPs) and interacting SNP pairs associated with these phenotypes were found and listed with empirical p-values.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
