Rohan Goli, Keerthana Komatineni, Shailesh Alluri, Nina Hubig, Hua Min, Yang Gong, Dean F Sittig, Lior Rennert, David Robinson, Paul Biondich, Adam Wright, Christian Nøhr, Timothy Law, Arild Faxvaag, Aneesa Weaver, Ronald Gimbel, Xia Jing
{"title":"Keyphrase Identification Using Minimal Labeled Data with Hierarchical Contexts and Transfer Learning.","authors":"Rohan Goli, Keerthana Komatineni, Shailesh Alluri, Nina Hubig, Hua Min, Yang Gong, Dean F Sittig, Lior Rennert, David Robinson, Paul Biondich, Adam Wright, Christian Nøhr, Timothy Law, Arild Faxvaag, Aneesa Weaver, Ronald Gimbel, Xia Jing","doi":"10.1101/2023.01.26.23285060","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Interoperable clinical decision support system (CDSS) rules provide a pathway to interoperability, a well-recognized challenge in health information technology. Building an ontology facilitates creating interoperable CDSS rules, which can be achieved by identifying the keyphrases (KP) from the existing literature. Ontology construction is traditionally a manual effort by human domain experts, and the newly advanced natural language processing techniques, such as KP identification, can be a critical complementary automatic part of building ontology. However, KP identification requires human expertise, consensus, and contextual understanding for data labeling.</p><p><strong>Methods: </strong>This paper presents a semi-supervised KP identification framework (long short-term memory-based encoders and the conditional random fields -based decoder models, BiLSTM-CRF) using minimal human labeled data based on hierarchical attention (i.e., at word, sentence, and abstract levels) over the documents and domain adaptation. We created synthetic labels for initial training and human-labeled data for fine-tuning. We also tested different options during NLP preprocessing and ML training to optimize the ML pipeline.</p><p><strong>Results: </strong>Our method outperforms the prior neural architectures by learning through synthetic labels for initial training, document-level contextual learning, language modeling, and fine-tuning with limited gold standard label data. After comparison, we found that the BIO encoding schema performed slightly better than Blue, and domain adaptation techniques can improve the quality of synthetic labels. In addition, document-level context, pre-trained LM, and pre-trained WE all contributed to better model performance in our tasks. Add 2 to 4 human-labeled documents for every 100 synthetic labeled documents improves the model performance without exhausting human-labeled documents too quickly.</p><p><strong>Conclusions: </strong>To the best of our knowledge, this is the first functional framework for the CDSS sub-domain to identify KPs, which is trained on limited human labeled data. It contributes to the general natural language processing (NLP) architectures in areas such as clinical NLP, where manual data labeling is challenging, and light-weighted deep learning models play an important role in real-time KP identification as a complementary approach to human experts' effort.</p>","PeriodicalId":18659,"journal":{"name":"medRxiv : the preprint server for health sciences","volume":" ","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2024-11-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/b9/97/nihpp-2023.01.26.23285060v2.PMC10246160.pdf","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"medRxiv : the preprint server for health sciences","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1101/2023.01.26.23285060","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Interoperable clinical decision support system (CDSS) rules provide a pathway to interoperability, a well-recognized challenge in health information technology. Building an ontology facilitates creating interoperable CDSS rules, which can be achieved by identifying the keyphrases (KP) from the existing literature. Ontology construction is traditionally a manual effort by human domain experts, and the newly advanced natural language processing techniques, such as KP identification, can be a critical complementary automatic part of building ontology. However, KP identification requires human expertise, consensus, and contextual understanding for data labeling.
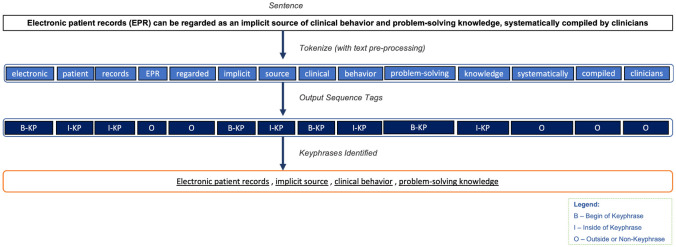
Methods: This paper presents a semi-supervised KP identification framework (long short-term memory-based encoders and the conditional random fields -based decoder models, BiLSTM-CRF) using minimal human labeled data based on hierarchical attention (i.e., at word, sentence, and abstract levels) over the documents and domain adaptation. We created synthetic labels for initial training and human-labeled data for fine-tuning. We also tested different options during NLP preprocessing and ML training to optimize the ML pipeline.
Results: Our method outperforms the prior neural architectures by learning through synthetic labels for initial training, document-level contextual learning, language modeling, and fine-tuning with limited gold standard label data. After comparison, we found that the BIO encoding schema performed slightly better than Blue, and domain adaptation techniques can improve the quality of synthetic labels. In addition, document-level context, pre-trained LM, and pre-trained WE all contributed to better model performance in our tasks. Add 2 to 4 human-labeled documents for every 100 synthetic labeled documents improves the model performance without exhausting human-labeled documents too quickly.
Conclusions: To the best of our knowledge, this is the first functional framework for the CDSS sub-domain to identify KPs, which is trained on limited human labeled data. It contributes to the general natural language processing (NLP) architectures in areas such as clinical NLP, where manual data labeling is challenging, and light-weighted deep learning models play an important role in real-time KP identification as a complementary approach to human experts' effort.




 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
