{"title":"otargen: GraphQL-based R package for tidy data accessing and processing from Open Targets Genetics.","authors":"Amir Feizi, Kamalika Ray","doi":"10.1093/bioinformatics/btad441","DOIUrl":null,"url":null,"abstract":"<p><strong>Motivation: </strong>Open Target Genetics is a comprehensive resource portal that offers variant-centric statistical evidence, enabling the prioritization of causal variants and the identification of potential drug targets. The portal uses GraphQL technology for efficient data query and provides endpoints for programmatic access for R and Python users. However, leveraging GraphQL for data retrieval can be challenging, time-consuming, and repetitive, requiring familiarity with the GraphQL query language and processing outputs in nested JSON (JavaScript Object Notation) format into tidy data tables. Therefore, developing open-source tools are required to simplify data retrieval processes to integrate valuable genetic information into data-driven target discovery pipelines seamlessly.</p><p><strong>Results: </strong>otargen is an open-source R package designed to make data retrieval and analysis from the Open Target Genetics portal as simple as possible for R users. The package offers a suite of functions covering all query types, allowing streamlined data access in a tidy table format. By executing only a single line of code, the otargen users avoid the repetitive scripting of complex GraphQL queries, including the post-processing steps. In addition, otargen contains convenient plotting functions to visualize and gain insights from complex data tables returned by several key functions.</p><p><strong>Availability and implementation: </strong>otargen is available at https://amirfeizi.github.io/otargen/.</p>","PeriodicalId":8903,"journal":{"name":"Bioinformatics","volume":"39 8","pages":""},"PeriodicalIF":5.4000,"publicationDate":"2023-08-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10394122/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Bioinformatics","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1093/bioinformatics/btad441","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"BIOCHEMICAL RESEARCH METHODS","Score":null,"Total":0}
引用次数: 0
Abstract
Motivation: Open Target Genetics is a comprehensive resource portal that offers variant-centric statistical evidence, enabling the prioritization of causal variants and the identification of potential drug targets. The portal uses GraphQL technology for efficient data query and provides endpoints for programmatic access for R and Python users. However, leveraging GraphQL for data retrieval can be challenging, time-consuming, and repetitive, requiring familiarity with the GraphQL query language and processing outputs in nested JSON (JavaScript Object Notation) format into tidy data tables. Therefore, developing open-source tools are required to simplify data retrieval processes to integrate valuable genetic information into data-driven target discovery pipelines seamlessly.
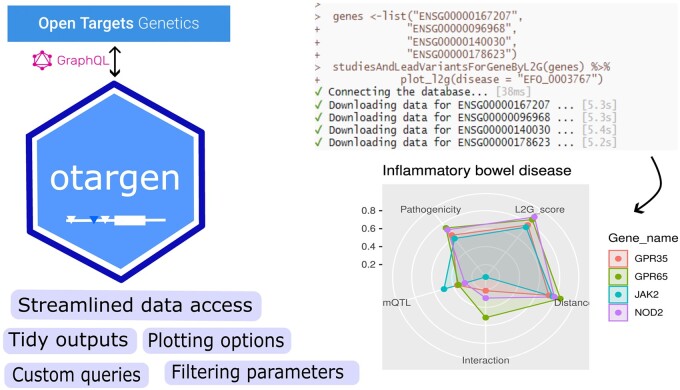
Results: otargen is an open-source R package designed to make data retrieval and analysis from the Open Target Genetics portal as simple as possible for R users. The package offers a suite of functions covering all query types, allowing streamlined data access in a tidy table format. By executing only a single line of code, the otargen users avoid the repetitive scripting of complex GraphQL queries, including the post-processing steps. In addition, otargen contains convenient plotting functions to visualize and gain insights from complex data tables returned by several key functions.
Availability and implementation: otargen is available at https://amirfeizi.github.io/otargen/.
期刊介绍:
The leading journal in its field, Bioinformatics publishes the highest quality scientific papers and review articles of interest to academic and industrial researchers. Its main focus is on new developments in genome bioinformatics and computational biology. Two distinct sections within the journal - Discovery Notes and Application Notes- focus on shorter papers; the former reporting biologically interesting discoveries using computational methods, the latter exploring the applications used for experiments.





 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
