Anand Maurya, Maciej Szymanski, Wojciech M Karlowski
{"title":"ARA: a flexible pipeline for automated exploration of NCBI SRA datasets.","authors":"Anand Maurya, Maciej Szymanski, Wojciech M Karlowski","doi":"10.1093/gigascience/giad067","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>One of the most effective and useful methods to explore the content of biological databases is searching with nucleotide or protein sequences as a query. However, especially in the case of nucleic acids, due to the large volume of data generated by the next-generation sequencing (NGS) technologies, this approach is often not available. The hierarchical organization of the NGS records is primarily designed for browsing or text-based searches of the information provided in metadata-related keywords, limiting the efficiency of database exploration.</p><p><strong>Findings: </strong>We developed an automated pipeline that incorporates the well-established NGS data-processing tools and procedures to allow easy and effective sampling of the NCBI SRA database records. Given a file with query nucleotide sequences, our tool estimates the matching content of SRA accessions by probing only a user-defined fraction of a record's sequences. Based on the selected parameters, it allows performing a full mapping experiment with records that meet the required criteria. The pipeline is designed to be easy to operate-it offers a fully automatic setup procedure and is fixed on tested supporting tools. The modular design and implemented usage modes allow a user to scale up the analyses into complex computational infrastructure.</p><p><strong>Conclusions: </strong>We present an easy-to-operate and automated tool that expands the way a user can access and explore the information contained within the records deposited in the NCBI SRA database.</p>","PeriodicalId":12581,"journal":{"name":"GigaScience","volume":"12 ","pages":""},"PeriodicalIF":11.8000,"publicationDate":"2022-12-28","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10433097/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"GigaScience","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1093/gigascience/giad067","RegionNum":2,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/8/17 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"MULTIDISCIPLINARY SCIENCES","Score":null,"Total":0}
引用次数: 0
Abstract
Background: One of the most effective and useful methods to explore the content of biological databases is searching with nucleotide or protein sequences as a query. However, especially in the case of nucleic acids, due to the large volume of data generated by the next-generation sequencing (NGS) technologies, this approach is often not available. The hierarchical organization of the NGS records is primarily designed for browsing or text-based searches of the information provided in metadata-related keywords, limiting the efficiency of database exploration.
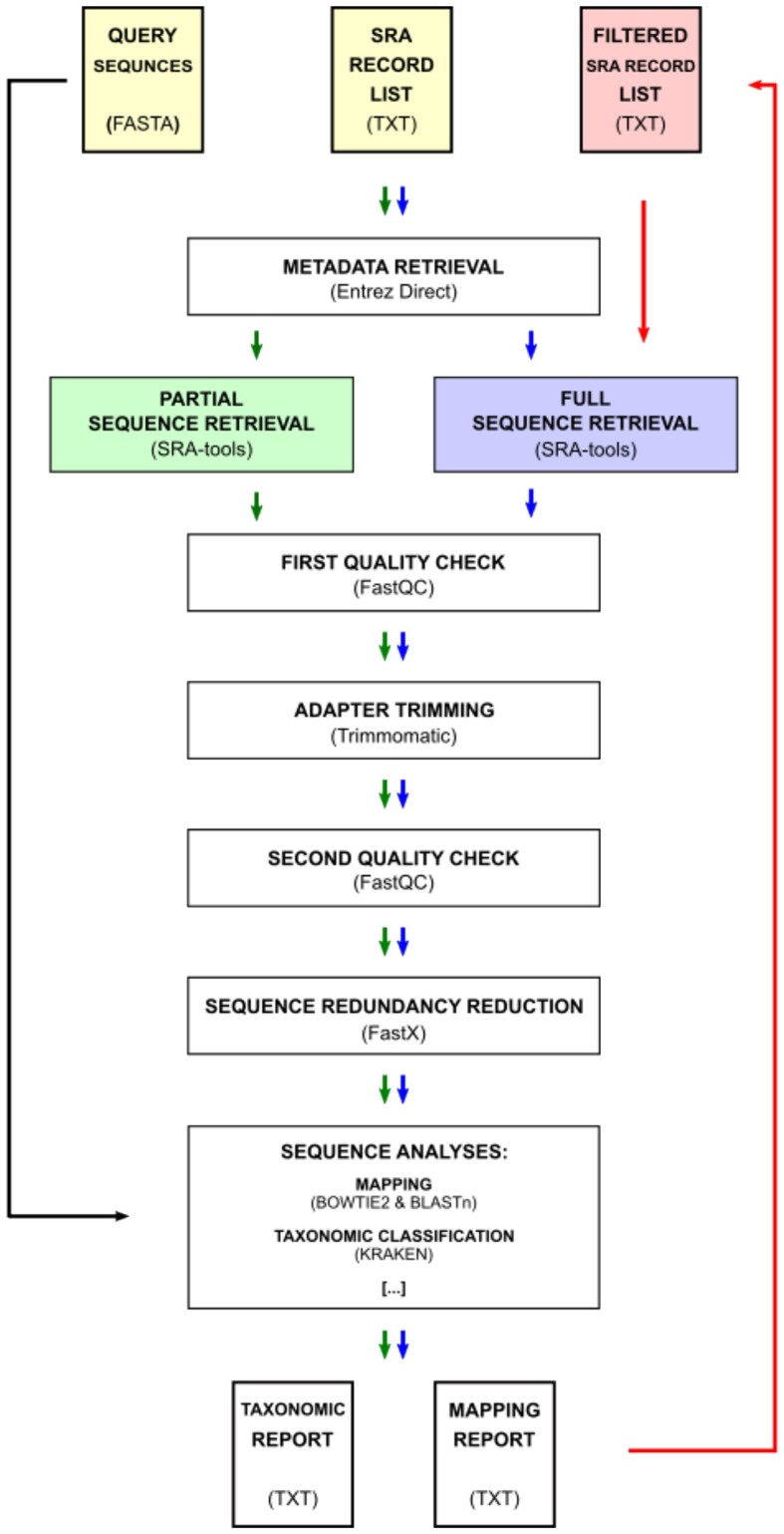
Findings: We developed an automated pipeline that incorporates the well-established NGS data-processing tools and procedures to allow easy and effective sampling of the NCBI SRA database records. Given a file with query nucleotide sequences, our tool estimates the matching content of SRA accessions by probing only a user-defined fraction of a record's sequences. Based on the selected parameters, it allows performing a full mapping experiment with records that meet the required criteria. The pipeline is designed to be easy to operate-it offers a fully automatic setup procedure and is fixed on tested supporting tools. The modular design and implemented usage modes allow a user to scale up the analyses into complex computational infrastructure.
Conclusions: We present an easy-to-operate and automated tool that expands the way a user can access and explore the information contained within the records deposited in the NCBI SRA database.
期刊介绍:
GigaScience seeks to transform data dissemination and utilization in the life and biomedical sciences. As an online open-access open-data journal, it specializes in publishing "big-data" studies encompassing various fields. Its scope includes not only "omic" type data and the fields of high-throughput biology currently serviced by large public repositories, but also the growing range of more difficult-to-access data, such as imaging, neuroscience, ecology, cohort data, systems biology and other new types of large-scale shareable data.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
