STIF: Intuitionistic fuzzy Gaussian membership function with statistical transformation weight of evidence and information value for private information preservation.
{"title":"STIF: Intuitionistic fuzzy Gaussian membership function with statistical transformation weight of evidence and information value for private information preservation.","authors":"G Sathish Kumar, K Premalatha","doi":"10.1007/s10619-023-07423-3","DOIUrl":null,"url":null,"abstract":"<p><p>Data sharing to the multiple organizations are essential for analysis in many situations. The shared data contains the individual's private and sensitive information and results in privacy breach. To overcome the privacy challenges, privacy preserving data mining (PPDM) has progressed as a solution. This work addresses the problem of PPDM by proposing statistical transformation with intuitionistic fuzzy (STIF) algorithm for data perturbation. The STIF algorithm contains statistical methods weight of evidence, information value and intuitionistic fuzzy Gaussian membership function. The STIF algorithm is applied on three benchmark datasets adult income, bank marketing and lung cancer. The classifier models decision tree, random forest, extreme gradient boost and support vector machines are used for accuracy and performance analysis. The results show that the STIF algorithm achieves 99% of accuracy for adult income dataset and 100% accuracy for both bank marketing and lung cancer datasets. Further, the results highlights that the STIF algorithm outperforms in data perturbation capacity and privacy preserving capacity than the state-of-art algorithms without any information loss on both numerical and categorical data.</p>","PeriodicalId":50568,"journal":{"name":"Distributed and Parallel Databases","volume":" ","pages":"1-34"},"PeriodicalIF":0.9000,"publicationDate":"2023-04-21","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10121075/pdf/","citationCount":"1","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Distributed and Parallel Databases","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10619-023-07423-3","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
引用次数: 1
Abstract
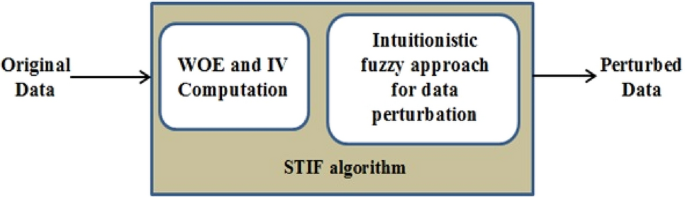
Data sharing to the multiple organizations are essential for analysis in many situations. The shared data contains the individual's private and sensitive information and results in privacy breach. To overcome the privacy challenges, privacy preserving data mining (PPDM) has progressed as a solution. This work addresses the problem of PPDM by proposing statistical transformation with intuitionistic fuzzy (STIF) algorithm for data perturbation. The STIF algorithm contains statistical methods weight of evidence, information value and intuitionistic fuzzy Gaussian membership function. The STIF algorithm is applied on three benchmark datasets adult income, bank marketing and lung cancer. The classifier models decision tree, random forest, extreme gradient boost and support vector machines are used for accuracy and performance analysis. The results show that the STIF algorithm achieves 99% of accuracy for adult income dataset and 100% accuracy for both bank marketing and lung cancer datasets. Further, the results highlights that the STIF algorithm outperforms in data perturbation capacity and privacy preserving capacity than the state-of-art algorithms without any information loss on both numerical and categorical data.
期刊介绍:
Distributed and Parallel Databases publishes papers in all the traditional as well as most emerging areas of database research, including:
Availability and reliability;
Benchmarking and performance evaluation, and tuning;
Big Data Storage and Processing;
Cloud Computing and Database-as-a-Service;
Crowdsourcing;
Data curation, annotation and provenance;
Data integration, metadata Management, and interoperability;
Data models, semantics, query languages;
Data mining and knowledge discovery;
Data privacy, security, trust;
Data provenance, workflows, Scientific Data Management;
Data visualization and interactive data exploration;
Data warehousing, OLAP, Analytics;
Graph data management, RDF, social networks;
Information Extraction and Data Cleaning;
Middleware and Workflow Management;
Modern Hardware and In-Memory Database Systems;
Query Processing and Optimization;
Semantic Web and open data;
Social Networks;
Storage, indexing, and physical database design;
Streams, sensor networks, and complex event processing;
Strings, Texts, and Keyword Search;
Spatial, temporal, and spatio-temporal databases;
Transaction processing;
Uncertain, probabilistic, and approximate databases.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
