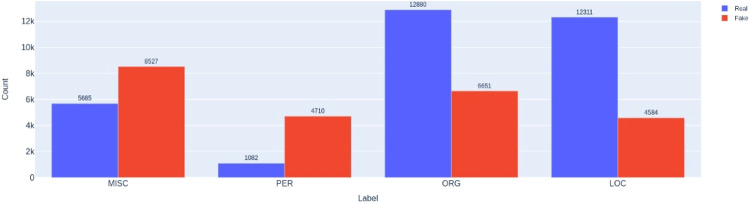
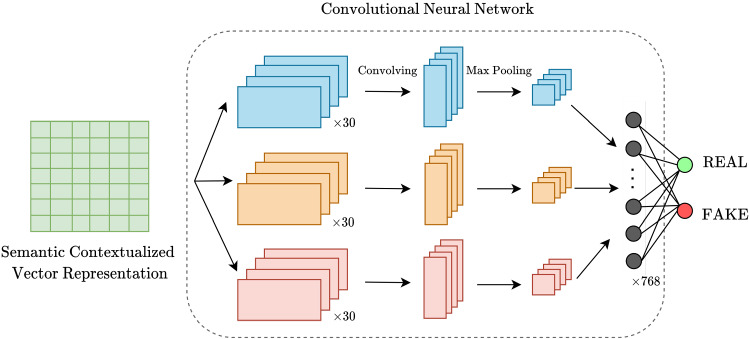
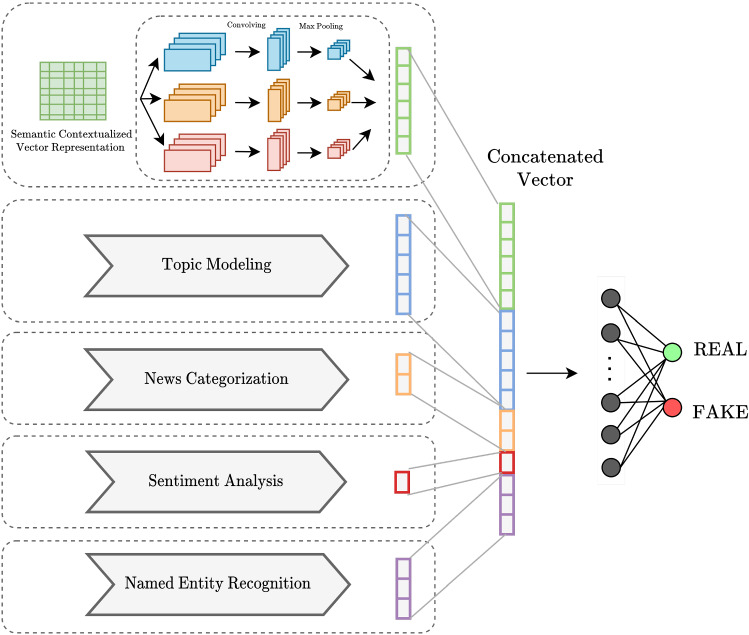
Due to the widespread use of social media, people are exposed to fake news and misinformation. Spreading fake news has adverse effects on both the general public and governments. This issue motivated researchers to utilize advanced natural language processing concepts to detect such misinformation in social media. Despite the recent research studies that only focused on semantic features extracted by deep contextualized text representation models, we aim to show that content-based feature engineering can enhance the semantic models in a complex task like fake news detection. These features can provide valuable information from different aspects of input texts and assist our neural classifier in detecting fake and real news more accurately than using semantic features. To substantiate the effectiveness of feature engineering besides semantic features, we proposed a deep neural architecture in which three parallel convolutional neural network (CNN) layers extract semantic features from contextual representation vectors. Then, semantic and content-based features are fed to a fully connected layer. We evaluated our model on an English dataset about the COVID-19 pandemic and a domain-independent Persian fake news dataset (TAJ). Our experiments on the English COVID-19 dataset show 4.16% and 4.02% improvement in accuracy and f1-score, respectively, compared to the baseline model, which does not benefit from the content-based features. We also achieved 2.01% and 0.69% improvement in accuracy and f1-score, respectively, compared to the state-of-the-art results reported by Shifath et al. (A transformer based approach for fighting covid-19 fake news, arXiv preprint arXiv:2101.12027, 2021). Our model outperformed the baseline on the TAJ dataset by improving accuracy and f1-score metrics by 1.89% and 1.74%, respectively. The model also shows 2.13% and 1.6% improvement in accuracy and f1-score, respectively, compared to the state-of-the-art model proposed by Samadi et al. (ACM Trans Asian Low-Resour Lang Inf Process, https://doi.org/10.1145/3472620, 2021).


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
