{"title":"STAR_outliers: a python package that separates univariate outliers from non-normal distributions.","authors":"John T Gregg, Jason H Moore","doi":"10.1186/s13040-023-00342-0","DOIUrl":null,"url":null,"abstract":"<p><p>There are not currently any univariate outlier detection algorithms that transform and model arbitrarily shaped distributions to remove univariate outliers. Some algorithms model skew, even fewer model kurtosis, and none of them model bimodality and monotonicity. To overcome these challenges, we have implemented an algorithm for Skew and Tail-heaviness Adjusted Removal of Outliers (STAR_outliers) that robustly removes univariate outliers from distributions with many different shape profiles, including extreme skew, extreme kurtosis, bimodality, and monotonicity. We show that STAR_outliers removes simulated outliers with greater recall and precision than several general algorithms, and it also models the outlier bounds of real data distributions with greater accuracy.Background Reliably removing univariate outliers from arbitrarily shaped distributions is a difficult task. Incorrectly assuming unimodality or overestimating tail heaviness fails to remove outliers, while underestimating tail heaviness incorrectly removes regular data from the tails. Skew often produces one heavy tail and one light tail, and we show that several sophisticated outlier removal algorithms often fail to remove outliers from the light tail. Multivariate outlier detection algorithms have recently become popular, but having tested PyOD's multivariate outlier removal algorithms, we found them to be inadequate for univariate outlier removal. They usually do not allow for univariate input, and they do not fit their distributions of outliership scores with a model on which an outlier threshold can be accurately established. Thus, there is a need for a flexible outlier removal algorithm that can model arbitrarily shaped univariate distributions.Results In order to effectively model arbitrarily shaped univariate distributions, we have combined several well-established algorithms into a new algorithm called STAR_outliers. STAR_outliers removes more simulated true outliers and fewer non-outliers than several other univariate algorithms. These include several normality-assuming outlier removal methods, PyOD's isolation forest (IF) outlier removal algorithm (ACM Transactions on Knowledge Discovery from Data (TKDD) 6:3, 2012) with default settings, and an IQR based algorithm by Verardi and Vermandele that removes outliers while accounting for skew and kurtosis (Verardi and Vermandele, Journal de la Société Française de Statistique 157:90-114, 2016). Since the IF algorithm's default model poorly fit the outliership scores, we also compared the isolation forest algorithm with a model that entails removing as many datapoints as STAR_outliers does in order of decreasing outliership scores. We also compared these algorithms on the publicly available 2018 National Health and Nutrition Examination Survey (NHANES) data by setting the outlier threshold to keep values falling within the main 99.3 percent of the fitted model's domain. We show that our STAR_outliers algorithm removes significantly closer to 0.7 percent of values from these features than other outlier removal methods on average.Conclusions STAR_outliers is an easily implemented python package for removing outliers that outperforms multiple commonly used methods of univariate outlier removal.</p>","PeriodicalId":48947,"journal":{"name":"Biodata Mining","volume":"16 1","pages":"25"},"PeriodicalIF":6.1000,"publicationDate":"2023-09-04","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10476292/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biodata Mining","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13040-023-00342-0","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
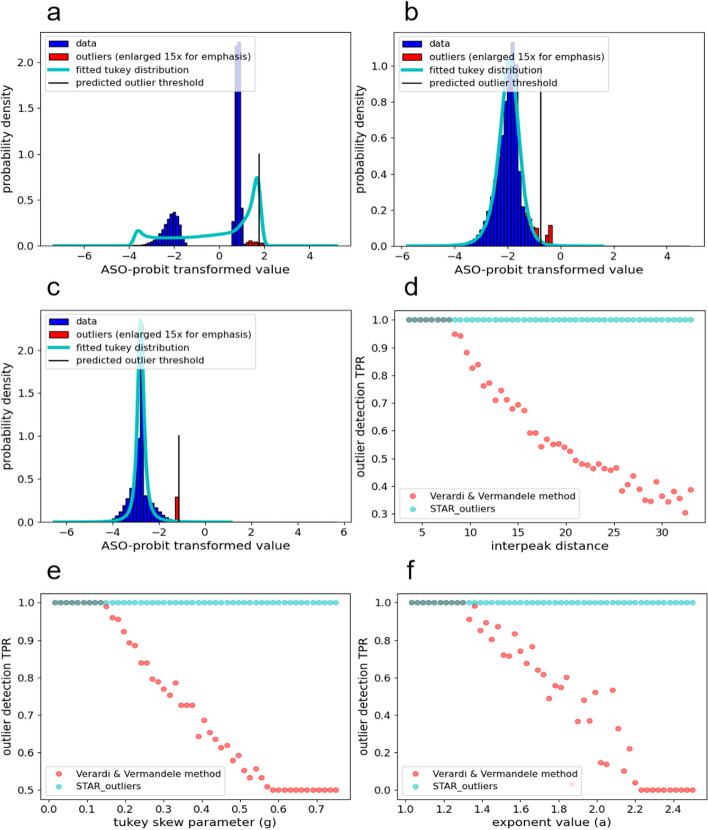
There are not currently any univariate outlier detection algorithms that transform and model arbitrarily shaped distributions to remove univariate outliers. Some algorithms model skew, even fewer model kurtosis, and none of them model bimodality and monotonicity. To overcome these challenges, we have implemented an algorithm for Skew and Tail-heaviness Adjusted Removal of Outliers (STAR_outliers) that robustly removes univariate outliers from distributions with many different shape profiles, including extreme skew, extreme kurtosis, bimodality, and monotonicity. We show that STAR_outliers removes simulated outliers with greater recall and precision than several general algorithms, and it also models the outlier bounds of real data distributions with greater accuracy.Background Reliably removing univariate outliers from arbitrarily shaped distributions is a difficult task. Incorrectly assuming unimodality or overestimating tail heaviness fails to remove outliers, while underestimating tail heaviness incorrectly removes regular data from the tails. Skew often produces one heavy tail and one light tail, and we show that several sophisticated outlier removal algorithms often fail to remove outliers from the light tail. Multivariate outlier detection algorithms have recently become popular, but having tested PyOD's multivariate outlier removal algorithms, we found them to be inadequate for univariate outlier removal. They usually do not allow for univariate input, and they do not fit their distributions of outliership scores with a model on which an outlier threshold can be accurately established. Thus, there is a need for a flexible outlier removal algorithm that can model arbitrarily shaped univariate distributions.Results In order to effectively model arbitrarily shaped univariate distributions, we have combined several well-established algorithms into a new algorithm called STAR_outliers. STAR_outliers removes more simulated true outliers and fewer non-outliers than several other univariate algorithms. These include several normality-assuming outlier removal methods, PyOD's isolation forest (IF) outlier removal algorithm (ACM Transactions on Knowledge Discovery from Data (TKDD) 6:3, 2012) with default settings, and an IQR based algorithm by Verardi and Vermandele that removes outliers while accounting for skew and kurtosis (Verardi and Vermandele, Journal de la Société Française de Statistique 157:90-114, 2016). Since the IF algorithm's default model poorly fit the outliership scores, we also compared the isolation forest algorithm with a model that entails removing as many datapoints as STAR_outliers does in order of decreasing outliership scores. We also compared these algorithms on the publicly available 2018 National Health and Nutrition Examination Survey (NHANES) data by setting the outlier threshold to keep values falling within the main 99.3 percent of the fitted model's domain. We show that our STAR_outliers algorithm removes significantly closer to 0.7 percent of values from these features than other outlier removal methods on average.Conclusions STAR_outliers is an easily implemented python package for removing outliers that outperforms multiple commonly used methods of univariate outlier removal.
目前还没有任何单变量离群点检测算法,可以对任意形状的分布进行变换和建模,以去除单变量离群点。有些算法建模偏态,甚至更少建模峰度,没有一个算法建模双峰性和单调性。为了克服这些挑战,我们实现了一种针对偏度和尾重调整的异常值去除(STAR_outliers)的算法,该算法可以从具有许多不同形状轮廓的分布中稳健地去除单变量异常值,包括极端偏度、极端峰度、双峰性和单调性。我们表明,STAR_outliers比几种通用算法具有更高的召回率和精度来去除模拟的异常值,并且它还以更高的精度建模真实数据分布的异常边界。从任意形状的分布中可靠地去除单变量异常值是一项艰巨的任务。错误地假设单峰性或高估尾重不能去除异常值,而低估尾重则错误地从尾部去除常规数据。偏态通常会产生一条重尾和一条轻尾,我们表明一些复杂的离群值去除算法通常不能从轻尾中去除离群值。多元离群值检测算法最近变得很流行,但在测试了PyOD的多元离群值去除算法后,我们发现它们对于单变量离群值去除是不够的。它们通常不允许单变量输入,并且它们的异常值分数分布不能与可以准确建立异常值阈值的模型相拟合。因此,需要一种灵活的离群值去除算法来模拟任意形状的单变量分布。为了有效地模拟任意形状的单变量分布,我们将几种成熟的算法组合成一个名为STAR_outliers的新算法。与其他几种单变量算法相比,STAR_outliers删除了更多模拟的真实异常值和更少的非异常值。其中包括几种假设正态性的离群值去除方法,PyOD的隔离森林(IF)离群值去除算法(ACM Transactions on Knowledge Discovery from Data (TKDD) 6:3, 2012)默认设置,以及Verardi和Vermandele基于IQR的算法,该算法在考虑偏态和峰度的同时去除离群值(Verardi和Vermandele, Journal de la sociacims francalaise de statisque 157:90-114, 2016)。由于IF算法的默认模型不能很好地拟合离群值得分,因此我们还将隔离森林算法与一个模型进行了比较,该模型需要删除尽可能多的数据点,如STAR_outliers按照离群值得分的递减顺序删除。我们还将这些算法与公开的2018年国家健康和营养检查调查(NHANES)数据进行了比较,设置了异常值阈值,使数值落在拟合模型域的99.3%以内。我们发现,平均而言,我们的STAR_outliers算法比其他离群值去除方法从这些特征中去除的值明显接近0.7%。STAR_outliers是一个易于实现的python包,用于去除异常值,优于多种常用的单变量异常值去除方法。
期刊介绍:
BioData Mining is an open access, open peer-reviewed journal encompassing research on all aspects of data mining applied to high-dimensional biological and biomedical data, focusing on computational aspects of knowledge discovery from large-scale genetic, transcriptomic, genomic, proteomic, and metabolomic data.
Topical areas include, but are not limited to:
-Development, evaluation, and application of novel data mining and machine learning algorithms.
-Adaptation, evaluation, and application of traditional data mining and machine learning algorithms.
-Open-source software for the application of data mining and machine learning algorithms.
-Design, development and integration of databases, software and web services for the storage, management, retrieval, and analysis of data from large scale studies.
-Pre-processing, post-processing, modeling, and interpretation of data mining and machine learning results for biological interpretation and knowledge discovery.





 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
