Jackson Callaghan, Colleen H Xu, Jiwen Xin, Marco Alvarado Cano, Anders Riutta, Eric Zhou, Rohan Juneja, Yao Yao, Madhumita Narayan, Kristina Hanspers, Ayushi Agrawal, Alexander R Pico, Chunlei Wu, Andrew I Su
{"title":"BioThings Explorer: a query engine for a federated knowledge graph of biomedical APIs.","authors":"Jackson Callaghan, Colleen H Xu, Jiwen Xin, Marco Alvarado Cano, Anders Riutta, Eric Zhou, Rohan Juneja, Yao Yao, Madhumita Narayan, Kristina Hanspers, Ayushi Agrawal, Alexander R Pico, Chunlei Wu, Andrew I Su","doi":"10.1093/bioinformatics/btad570","DOIUrl":null,"url":null,"abstract":"<p><strong>Summary: </strong>Knowledge graphs are an increasingly common data structure for representing biomedical information. These knowledge graphs can easily represent heterogeneous types of information, and many algorithms and tools exist for querying and analyzing graphs. Biomedical knowledge graphs have been used in a variety of applications, including drug repurposing, identification of drug targets, prediction of drug side effects, and clinical decision support. Typically, knowledge graphs are constructed by centralization and integration of data from multiple disparate sources. Here, we describe BioThings Explorer, an application that can query a virtual, federated knowledge graph derived from the aggregated information in a network of biomedical web services. BioThings Explorer leverages semantically precise annotations of the inputs and outputs for each resource, and automates the chaining of web service calls to execute multi-step graph queries. Because there is no large, centralized knowledge graph to maintain, BioThings Explorer is distributed as a lightweight application that dynamically retrieves information at query time.</p><p><strong>Availability and implementation: </strong>More information can be found at https://explorer.biothings.io and code is available at https://github.com/biothings/biothings_explorer.</p>","PeriodicalId":8903,"journal":{"name":"Bioinformatics","volume":" ","pages":""},"PeriodicalIF":5.4000,"publicationDate":"2023-09-02","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11015316/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Bioinformatics","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1093/bioinformatics/btad570","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"BIOCHEMICAL RESEARCH METHODS","Score":null,"Total":0}
引用次数: 0
Abstract
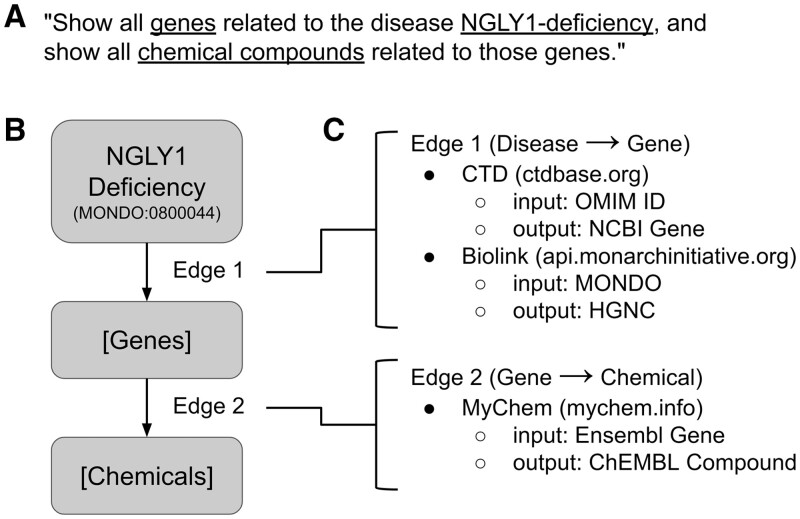
Summary: Knowledge graphs are an increasingly common data structure for representing biomedical information. These knowledge graphs can easily represent heterogeneous types of information, and many algorithms and tools exist for querying and analyzing graphs. Biomedical knowledge graphs have been used in a variety of applications, including drug repurposing, identification of drug targets, prediction of drug side effects, and clinical decision support. Typically, knowledge graphs are constructed by centralization and integration of data from multiple disparate sources. Here, we describe BioThings Explorer, an application that can query a virtual, federated knowledge graph derived from the aggregated information in a network of biomedical web services. BioThings Explorer leverages semantically precise annotations of the inputs and outputs for each resource, and automates the chaining of web service calls to execute multi-step graph queries. Because there is no large, centralized knowledge graph to maintain, BioThings Explorer is distributed as a lightweight application that dynamically retrieves information at query time.
Availability and implementation: More information can be found at https://explorer.biothings.io and code is available at https://github.com/biothings/biothings_explorer.
期刊介绍:
The leading journal in its field, Bioinformatics publishes the highest quality scientific papers and review articles of interest to academic and industrial researchers. Its main focus is on new developments in genome bioinformatics and computational biology. Two distinct sections within the journal - Discovery Notes and Application Notes- focus on shorter papers; the former reporting biologically interesting discoveries using computational methods, the latter exploring the applications used for experiments.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
