Sana Nazari Nezhad, Mohammad H Zahedi, Elham Farahani
{"title":"Detecting diseases in medical prescriptions using data mining methods.","authors":"Sana Nazari Nezhad, Mohammad H Zahedi, Elham Farahani","doi":"10.1186/s13040-022-00314-w","DOIUrl":null,"url":null,"abstract":"<p><p>Every year, the health of millions of people around the world is compromised by misdiagnosis, which sometimes could even lead to death. In addition, it entails huge financial costs for patients, insurance companies, and governments. Furthermore, many physicians' professional life is adversely affected by unintended errors in prescribing medication or misdiagnosing a disease. Our aim in this paper is to use data mining methods to find knowledge in a dataset of medical prescriptions that can be effective in improving the diagnostic process. In this study, using 4 single classification algorithms including decision tree, random forest, simple Bayes, and K-nearest neighbors, the disease and its category were predicted. Then, in order to improve the performance of these algorithms, we used an Ensemble Learning methodology to present our proposed model. In the final step, a number of experiments were performed to compare the performance of different data mining techniques. The final model proposed in this study has an accuracy and kappa score of 62.86% and 0.620 for disease prediction and 74.39% and 0.720 for prediction of the disease category, respectively, which has better performance than other studies in this field.In general, the results of this study can be used to help maintain the health of patients, and prevent the wastage of the financial resources of patients, insurance companies, and governments. In addition, it can aid physicians and help their careers by providing timely information on diagnostic errors. Finally, these results can be used as a basis for future research in this field.</p>","PeriodicalId":48947,"journal":{"name":"Biodata Mining","volume":"15 1","pages":"29"},"PeriodicalIF":6.1000,"publicationDate":"2022-11-24","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9694862/pdf/","citationCount":"2","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biodata Mining","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13040-022-00314-w","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 2
Abstract
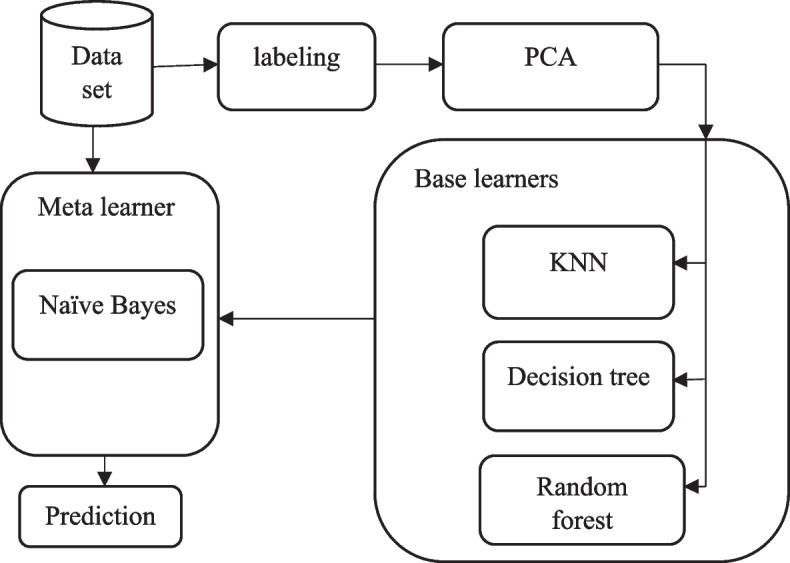
Every year, the health of millions of people around the world is compromised by misdiagnosis, which sometimes could even lead to death. In addition, it entails huge financial costs for patients, insurance companies, and governments. Furthermore, many physicians' professional life is adversely affected by unintended errors in prescribing medication or misdiagnosing a disease. Our aim in this paper is to use data mining methods to find knowledge in a dataset of medical prescriptions that can be effective in improving the diagnostic process. In this study, using 4 single classification algorithms including decision tree, random forest, simple Bayes, and K-nearest neighbors, the disease and its category were predicted. Then, in order to improve the performance of these algorithms, we used an Ensemble Learning methodology to present our proposed model. In the final step, a number of experiments were performed to compare the performance of different data mining techniques. The final model proposed in this study has an accuracy and kappa score of 62.86% and 0.620 for disease prediction and 74.39% and 0.720 for prediction of the disease category, respectively, which has better performance than other studies in this field.In general, the results of this study can be used to help maintain the health of patients, and prevent the wastage of the financial resources of patients, insurance companies, and governments. In addition, it can aid physicians and help their careers by providing timely information on diagnostic errors. Finally, these results can be used as a basis for future research in this field.
期刊介绍:
BioData Mining is an open access, open peer-reviewed journal encompassing research on all aspects of data mining applied to high-dimensional biological and biomedical data, focusing on computational aspects of knowledge discovery from large-scale genetic, transcriptomic, genomic, proteomic, and metabolomic data.
Topical areas include, but are not limited to:
-Development, evaluation, and application of novel data mining and machine learning algorithms.
-Adaptation, evaluation, and application of traditional data mining and machine learning algorithms.
-Open-source software for the application of data mining and machine learning algorithms.
-Design, development and integration of databases, software and web services for the storage, management, retrieval, and analysis of data from large scale studies.
-Pre-processing, post-processing, modeling, and interpretation of data mining and machine learning results for biological interpretation and knowledge discovery.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
