{"title":"Word2vec neural model-based technique to generate protein vectors for combating COVID-19: a machine learning approach.","authors":"Toby A Adjuik, Daniel Ananey-Obiri","doi":"10.1007/s41870-022-00949-2","DOIUrl":null,"url":null,"abstract":"<p><p>The world was ambushed in 2019 by the COVID-19 virus which affected the health, economy, and lifestyle of individuals worldwide. One way of combating such a public health concern is by using appropriate, rapid, and unbiased diagnostic tools for quick detection of infected people. However, a current dearth of bioinformatics tools necessitates modeling studies to help diagnose COVID-19 cases. Molecular-based methods such as the real-time reverse transcription polymerase chain reaction (rRT-PCR) for detecting COVID-19 is time consuming and prone to contamination. Modern bioinformatics tools have made it possible to create large databases of protein sequences of various diseases, apply data mining techniques, and accurately diagnose diseases. However, the current sequence alignment tools that use these databases are not able to detect novel COVID-19 viral sequences due to high sequence dissimilarity. The objective of this study, therefore, was to develop models that can accurately classify COVID-19 viral sequences rapidly using protein vectors generated by neural word embedding technique. Five machine learning models; K nearest neighbor regression (KNN), support vector machine (SVM), random forest (RF), Linear discriminant analysis (LDA), and Logistic regression were developed using datasets from the National Center for Biotechnology. Our results suggest, the RF model performed better than all other models on the training dataset with 99% accuracy score and 99.5% accuracy on the testing dataset. The implication of this study is that, rapid detection of the COVID-19 virus in suspected cases could potentially save lives as less time will be needed to ascertain the status of a patient.</p>","PeriodicalId":73455,"journal":{"name":"International journal of information technology : an official journal of Bharati Vidyapeeth's Institute of Computer Applications and Management","volume":"14 7","pages":"3291-3299"},"PeriodicalIF":0.0000,"publicationDate":"2022-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9119569/pdf/","citationCount":"11","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"International journal of information technology : an official journal of Bharati Vidyapeeth's Institute of Computer Applications and Management","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s41870-022-00949-2","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 11
Abstract
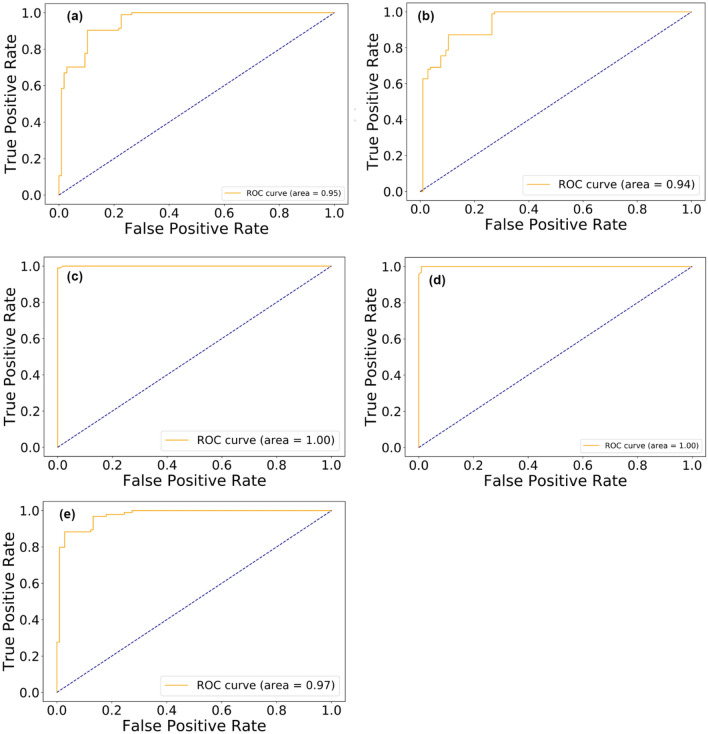
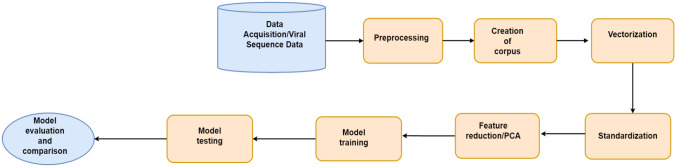
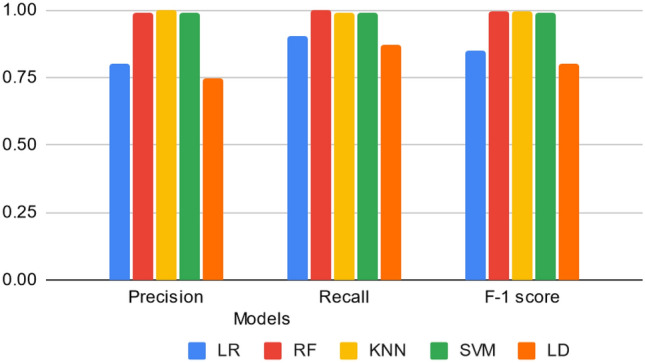
The world was ambushed in 2019 by the COVID-19 virus which affected the health, economy, and lifestyle of individuals worldwide. One way of combating such a public health concern is by using appropriate, rapid, and unbiased diagnostic tools for quick detection of infected people. However, a current dearth of bioinformatics tools necessitates modeling studies to help diagnose COVID-19 cases. Molecular-based methods such as the real-time reverse transcription polymerase chain reaction (rRT-PCR) for detecting COVID-19 is time consuming and prone to contamination. Modern bioinformatics tools have made it possible to create large databases of protein sequences of various diseases, apply data mining techniques, and accurately diagnose diseases. However, the current sequence alignment tools that use these databases are not able to detect novel COVID-19 viral sequences due to high sequence dissimilarity. The objective of this study, therefore, was to develop models that can accurately classify COVID-19 viral sequences rapidly using protein vectors generated by neural word embedding technique. Five machine learning models; K nearest neighbor regression (KNN), support vector machine (SVM), random forest (RF), Linear discriminant analysis (LDA), and Logistic regression were developed using datasets from the National Center for Biotechnology. Our results suggest, the RF model performed better than all other models on the training dataset with 99% accuracy score and 99.5% accuracy on the testing dataset. The implication of this study is that, rapid detection of the COVID-19 virus in suspected cases could potentially save lives as less time will be needed to ascertain the status of a patient.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
