{"title":"Hybrid optimization and ontology-based semantic model for efficient text-based information retrieval.","authors":"Ram Kumar, S C Sharma","doi":"10.1007/s11227-022-04708-9","DOIUrl":null,"url":null,"abstract":"<p><p>Query expansion is an important approach utilized to improve the efficiency of data retrieval tasks. Numerous works are carried out by the researchers to generate fair constructive results; however, they do not provide acceptable results for all kinds of queries particularly phrase and individual queries. The utilization of identical data sources and weighting strategies for expanding such terms are the major cause of this issue which leads the model unable to capture the comprehensive relationship between the query terms. In order to tackle this issue, we developed a novel approach for query expansion technique to analyze the different data sources namely WordNet, Wikipedia, and Text REtrieval Conference. This paper presents an Improved Aquila Optimization-based COOT(IAOCOOT) algorithm for query expansion which retrieves the semantic aspects that match the query term. The semantic heterogeneity associated with document retrieval mainly impacts the relevance matching between the query and the document. The main cause of this issue is that the similarity among the words is not evaluated correctly. To overcome this problem, we are using a Modified Needleman Wunsch algorithm algorithm to deal with the problems of uncertainty, imprecision in the information retrieval process, and semantic ambiguity of indexed terms in both the local and global perspectives. The k most similar word is determined and returned from a candidate set through the top-k words selection technique and it is widely utilized in different tasks. The proposed IAOCOOT model is evaluated using different standard Information Retrieval performance metrics to compute the validity of the proposed work by comparing it with other state-of-art techniques.</p>","PeriodicalId":50034,"journal":{"name":"Journal of Supercomputing","volume":"79 2","pages":"2251-2280"},"PeriodicalIF":2.7000,"publicationDate":"2023-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9364863/pdf/","citationCount":"9","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Supercomputing","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s11227-022-04708-9","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, HARDWARE & ARCHITECTURE","Score":null,"Total":0}
引用次数: 9
Abstract
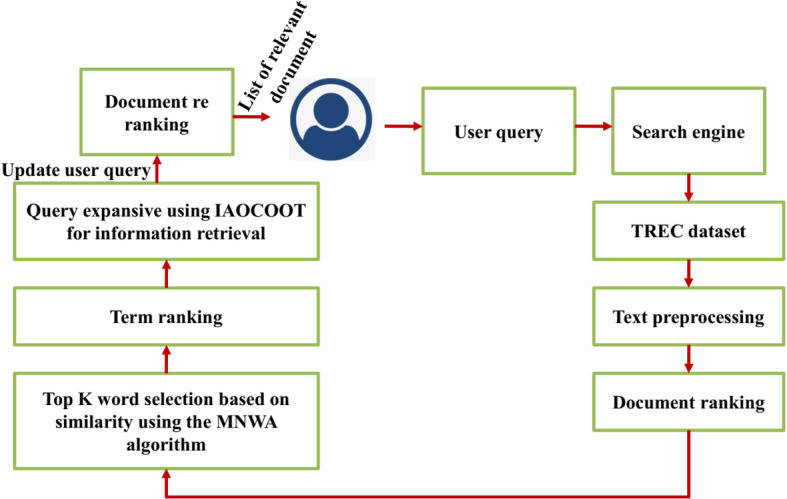
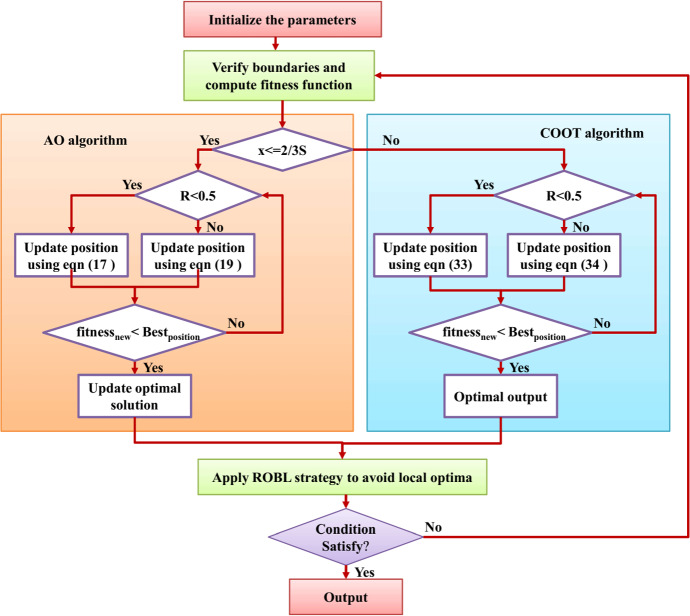
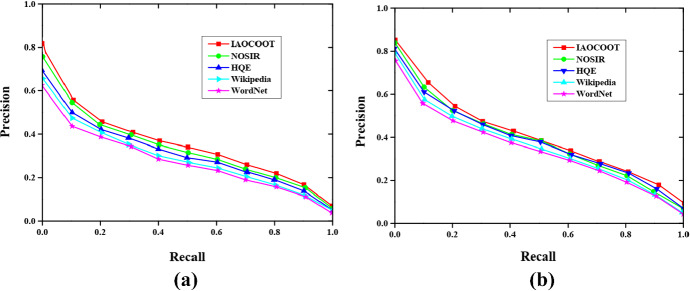
Query expansion is an important approach utilized to improve the efficiency of data retrieval tasks. Numerous works are carried out by the researchers to generate fair constructive results; however, they do not provide acceptable results for all kinds of queries particularly phrase and individual queries. The utilization of identical data sources and weighting strategies for expanding such terms are the major cause of this issue which leads the model unable to capture the comprehensive relationship between the query terms. In order to tackle this issue, we developed a novel approach for query expansion technique to analyze the different data sources namely WordNet, Wikipedia, and Text REtrieval Conference. This paper presents an Improved Aquila Optimization-based COOT(IAOCOOT) algorithm for query expansion which retrieves the semantic aspects that match the query term. The semantic heterogeneity associated with document retrieval mainly impacts the relevance matching between the query and the document. The main cause of this issue is that the similarity among the words is not evaluated correctly. To overcome this problem, we are using a Modified Needleman Wunsch algorithm algorithm to deal with the problems of uncertainty, imprecision in the information retrieval process, and semantic ambiguity of indexed terms in both the local and global perspectives. The k most similar word is determined and returned from a candidate set through the top-k words selection technique and it is widely utilized in different tasks. The proposed IAOCOOT model is evaluated using different standard Information Retrieval performance metrics to compute the validity of the proposed work by comparing it with other state-of-art techniques.
期刊介绍:
The Journal of Supercomputing publishes papers on the technology, architecture and systems, algorithms, languages and programs, performance measures and methods, and applications of all aspects of Supercomputing. Tutorial and survey papers are intended for workers and students in the fields associated with and employing advanced computer systems. The journal also publishes letters to the editor, especially in areas relating to policy, succinct statements of paradoxes, intuitively puzzling results, partial results and real needs.
Published theoretical and practical papers are advanced, in-depth treatments describing new developments and new ideas. Each includes an introduction summarizing prior, directly pertinent work that is useful for the reader to understand, in order to appreciate the advances being described.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
