{"title":"Text embedding techniques for efficient clustering of twitter data.","authors":"Jayasree Ravi, Sushil Kulkarni","doi":"10.1007/s12065-023-00825-3","DOIUrl":null,"url":null,"abstract":"<p><p>World wide web is abundant with various types of information such blogs, social media posts, news articles. With this type of magnitude of online content, there is a need to deeply understand the insights of it in order to make use of the information for practical applications such as event detection, polarity, sentiment analysis and so on. Natural Language Processing (NLP) is the study of such information which is used for text classification, sentiment analysis, clustering of similar text. NLP makes use of linguistic knowledge and build machine learning models to analyse textual information. NLP finds its way in various applications like classification of online review into positive and negative without actually reading the reviews and feedback. For text analysis, there should be a way to quantify the text based on its frequency of occurrence, correlation with neighbouring words, contextual similarity of words, etc. One such way is word embedding. This study applies various word embedding techniques on tweets of popular news channels and clusters the resultant vectors using K-means algorithm. From this study, it is found out that Bidirectional Encoder Representations from Transformers (BERT) has achieved highest accuracy rate when used with K-means clustering.</p>","PeriodicalId":46237,"journal":{"name":"Evolutionary Intelligence","volume":" ","pages":"1-11"},"PeriodicalIF":2.6000,"publicationDate":"2023-02-07","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9904526/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Evolutionary Intelligence","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s12065-023-00825-3","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
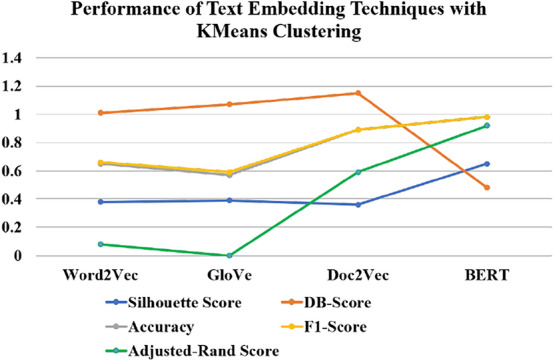
World wide web is abundant with various types of information such blogs, social media posts, news articles. With this type of magnitude of online content, there is a need to deeply understand the insights of it in order to make use of the information for practical applications such as event detection, polarity, sentiment analysis and so on. Natural Language Processing (NLP) is the study of such information which is used for text classification, sentiment analysis, clustering of similar text. NLP makes use of linguistic knowledge and build machine learning models to analyse textual information. NLP finds its way in various applications like classification of online review into positive and negative without actually reading the reviews and feedback. For text analysis, there should be a way to quantify the text based on its frequency of occurrence, correlation with neighbouring words, contextual similarity of words, etc. One such way is word embedding. This study applies various word embedding techniques on tweets of popular news channels and clusters the resultant vectors using K-means algorithm. From this study, it is found out that Bidirectional Encoder Representations from Transformers (BERT) has achieved highest accuracy rate when used with K-means clustering.
期刊介绍:
This Journal provides an international forum for the timely publication and dissemination of foundational and applied research in the domain of Evolutionary Intelligence. The spectrum of emerging fields in contemporary artificial intelligence, including Big Data, Deep Learning, Computational Neuroscience bridged with evolutionary computing and other population-based search methods constitute the flag of Evolutionary Intelligence Journal.Topics of interest for Evolutionary Intelligence refer to different aspects of evolutionary models of computation empowered with intelligence-based approaches, including but not limited to architectures, model optimization and tuning, machine learning algorithms, life inspired adaptive algorithms, swarm-oriented strategies, high performance computing, massive data processing, with applications to domains like computer vision, image processing, simulation, robotics, computational finance, media, internet of things, medicine, bioinformatics, smart cities, and similar. Surveys outlining the state of art in specific subfields and applications are welcome.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
