{"title":"NILC-Metrix: assessing the complexity of written and spoken language in Brazilian Portuguese","authors":"Sidney Evaldo Leal, Magali Sanches Duran, Carolina Evaristo Scarton, Nathan Siegle Hartmann, Sandra Maria Aluísio","doi":"10.1007/s10579-023-09693-w","DOIUrl":null,"url":null,"abstract":"The objective of this paper is to present and make publicly available the NILC-Metrix, a computational system comprising 200 metrics proposed in studies on discourse, psycholinguistics, cognitive and computational linguistics, to assess textual complexity in Brazilian Portuguese (BP). The metrics are relevant for descriptive analysis and the creation of computational models and can be used to extract information from various linguistic levels of written and spoken language. The metrics were developed during the last 13 years, starting in the end of 2007, within the scope of the PorSimples project. Once the PorSimples finished, new metrics were added to the initial 48 metrics of the Coh-Metrix-Port tool. Coh-Metrix-Port adapted some metrics to BP from the Coh-Metrix tool that computes metrics related to cohesion and coherence of texts in English. Given the large number of metrics, we present them following an organisation similar to the metrics of Coh-Metrix v3.0 to facilitate comparisons made with metrics in Portuguese and English, in future studies using both tools. In this paper, we illustrate the potential of the NILC-Metrix by presenting three applications: (i) a descriptive analysis of the differences between children’s film subtitles and texts written for Elementary School I (comprises classes from 1st to 5th grade) and II (Final Years) (comprises classes from 6th to 9th grade, in an age group that corresponds to the transition between childhood and adolescence); (ii) a new predictor of textual complexity for the corpus of original and simplified texts of the PorSimples project; (iii) a complexity prediction model for school grades, using transcripts of children’s story narratives told by teenagers. For each application, we evaluate which groups of metrics are more discriminative, showing their contribution for each task.","PeriodicalId":49927,"journal":{"name":"Language Resources and Evaluation","volume":"10 1","pages":"0"},"PeriodicalIF":1.7000,"publicationDate":"2023-10-17","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"5","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Language Resources and Evaluation","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s10579-023-09693-w","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
引用次数: 5
Abstract
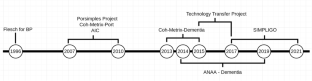
The objective of this paper is to present and make publicly available the NILC-Metrix, a computational system comprising 200 metrics proposed in studies on discourse, psycholinguistics, cognitive and computational linguistics, to assess textual complexity in Brazilian Portuguese (BP). The metrics are relevant for descriptive analysis and the creation of computational models and can be used to extract information from various linguistic levels of written and spoken language. The metrics were developed during the last 13 years, starting in the end of 2007, within the scope of the PorSimples project. Once the PorSimples finished, new metrics were added to the initial 48 metrics of the Coh-Metrix-Port tool. Coh-Metrix-Port adapted some metrics to BP from the Coh-Metrix tool that computes metrics related to cohesion and coherence of texts in English. Given the large number of metrics, we present them following an organisation similar to the metrics of Coh-Metrix v3.0 to facilitate comparisons made with metrics in Portuguese and English, in future studies using both tools. In this paper, we illustrate the potential of the NILC-Metrix by presenting three applications: (i) a descriptive analysis of the differences between children’s film subtitles and texts written for Elementary School I (comprises classes from 1st to 5th grade) and II (Final Years) (comprises classes from 6th to 9th grade, in an age group that corresponds to the transition between childhood and adolescence); (ii) a new predictor of textual complexity for the corpus of original and simplified texts of the PorSimples project; (iii) a complexity prediction model for school grades, using transcripts of children’s story narratives told by teenagers. For each application, we evaluate which groups of metrics are more discriminative, showing their contribution for each task.
期刊介绍:
Language Resources and Evaluation is the first publication devoted to the acquisition, creation, annotation, and use of language resources, together with methods for evaluation of resources, technologies, and applications.
Language resources include language data and descriptions in machine readable form used to assist and augment language processing applications, such as written or spoken corpora and lexica, multimodal resources, grammars, terminology or domain specific databases and dictionaries, ontologies, multimedia databases, etc., as well as basic software tools for their acquisition, preparation, annotation, management, customization, and use.
Evaluation of language resources concerns assessing the state-of-the-art for a given technology, comparing different approaches to a given problem, assessing the availability of resources and technologies for a given application, benchmarking, and assessing system usability and user satisfaction.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
