{"title":"Temperature impact on the economic growth effect: method development and model performance evaluation with subnational data in China","authors":"Yu Song, Zhihua Pan, Fei Lun, Buju Long, Siyu Liu, Guolin Han, Jialin Wang, Na Huang, Ziyuan Zhang, Shangqian Ma, Guofeng Sun, Cong Liu","doi":"10.1140/epjds/s13688-023-00425-2","DOIUrl":null,"url":null,"abstract":"Abstract Temperature-economic growth relationships are computed to quantify the impact of climate change on the economy. However, model performance and differences of predictions among research complicate the use of climate econometric estimation. Machine learning methods provide an alternative that might improve the predictive effects. However, time series and extrapolation issues constrain methods such as random forests. We apply a simple thought experiment with national marginal GDP growth by aggregating subnational climate impact to alleviate the shortcomings in random forests. This paper uses random forests, multivariate cubic regression, and linear spline regression to examine the direct impacts of temperature on economic development and conducts a performance comparison of the methods. The model results indicate an optimal temperature of 15°C, 15°C or 21°C for each model. Furthermore, a thought experiment indicates that the marginal predictions of national GDP changes by approximately 1%, −3%, or −6% for models with 1°C warming. The performance comparison suggests that random forests have stable model performance and better prediction performance in bootstrapping. However, the extrapolation problem in random forests causes underestimation of climate impact in 5% of cells under 6°C warming. Overall, our results suggest that temperature should be considered in economic projections under climate change scenarios. We also suggest the use of more machine learning methods in climate impact assessment.","PeriodicalId":11887,"journal":{"name":"EPJ Data Science","volume":"13 5","pages":"0"},"PeriodicalIF":2.5000,"publicationDate":"2023-10-27","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"EPJ Data Science","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1140/epjds/s13688-023-00425-2","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICS, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
引用次数: 0
Abstract
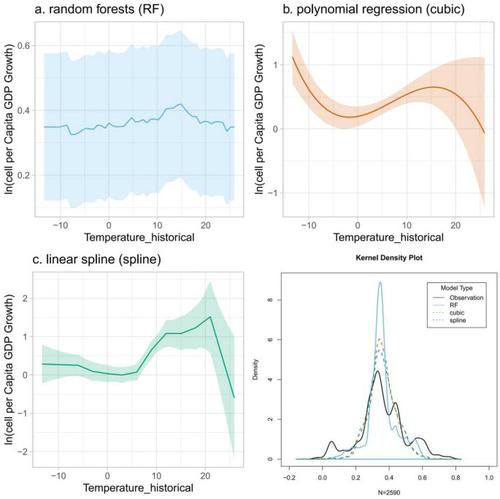
Abstract Temperature-economic growth relationships are computed to quantify the impact of climate change on the economy. However, model performance and differences of predictions among research complicate the use of climate econometric estimation. Machine learning methods provide an alternative that might improve the predictive effects. However, time series and extrapolation issues constrain methods such as random forests. We apply a simple thought experiment with national marginal GDP growth by aggregating subnational climate impact to alleviate the shortcomings in random forests. This paper uses random forests, multivariate cubic regression, and linear spline regression to examine the direct impacts of temperature on economic development and conducts a performance comparison of the methods. The model results indicate an optimal temperature of 15°C, 15°C or 21°C for each model. Furthermore, a thought experiment indicates that the marginal predictions of national GDP changes by approximately 1%, −3%, or −6% for models with 1°C warming. The performance comparison suggests that random forests have stable model performance and better prediction performance in bootstrapping. However, the extrapolation problem in random forests causes underestimation of climate impact in 5% of cells under 6°C warming. Overall, our results suggest that temperature should be considered in economic projections under climate change scenarios. We also suggest the use of more machine learning methods in climate impact assessment.
期刊介绍:
EPJ Data Science covers a broad range of research areas and applications and particularly encourages contributions from techno-socio-economic systems, where it comprises those research lines that now regard the digital “tracks” of human beings as first-order objects for scientific investigation. Topics include, but are not limited to, human behavior, social interaction (including animal societies), economic and financial systems, management and business networks, socio-technical infrastructure, health and environmental systems, the science of science, as well as general risk and crisis scenario forecasting up to and including policy advice.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
