{"title":"PartCom: Part Composition Learning for 3D Open-Set Recognition","authors":"Tingyu Weng, Jun Xiao, Hao Pan, Haiyong Jiang","doi":"10.1007/s11263-023-01947-y","DOIUrl":null,"url":null,"abstract":"<p>In this work, we address 3D open-set recognition (OSR) that can recognize known classes as well as be aware of unknown classes during testing. The key challenge of 3D OSR is that unknown objects are not available during training and 3D closed set recognition methods trained on known classes usually classify an unknown object as a known one with high confidence. This over-confidence is mainly due to the fact that local part information in 3D shapes provides the main evidence for known class recognition, which nevertheless leads to the incorrect recognition of unknown classes that have similar local parts but arranged very differently. To address this problem, we propose <i>PartCom</i>, a 3D OSR method that calls attention to not only part information but also the part composition that is unique to each class. <i>PartCom</i> uses a part codebook to learn the different parts across object classes, and represents part composition as a latent distribution over the codebook. In this way, both known classes and unknown classes are cast into the space of learned parts, but known classes have composites largely distinguished from unknown ones, which enables OSR. To learn the part codebook, we formulate two necessary constraints to ensure the part codebook encodes diverse parts of different classes compactly and efficiently. In addition, we propose an optional augmenting module of <i>Part-aware Unknown feaTure Synthesis</i>, that further reduces open-set misclassification risks by synthesizing novel part compositions to be regarded as unknown classes. This synthesis is simply achieved by mixing part codes of different classes; training with such augmented data makes classifiers’ decision boundaries more closely fit the known classes and therefore improves open-set recognition. To evaluate the proposed method, we construct four 3D OSR tasks based on datasets of CAD shapes, multi-view scanned shapes, and LiDAR scanned shapes. Extensive experiments show that our method achieves significantly superior results than SOTA baselines on all tasks.</p>","PeriodicalId":13752,"journal":{"name":"International Journal of Computer Vision","volume":"83 20","pages":""},"PeriodicalIF":9.3000,"publicationDate":"2023-11-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"International Journal of Computer Vision","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s11263-023-01947-y","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
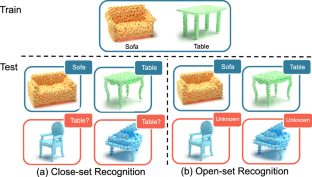
In this work, we address 3D open-set recognition (OSR) that can recognize known classes as well as be aware of unknown classes during testing. The key challenge of 3D OSR is that unknown objects are not available during training and 3D closed set recognition methods trained on known classes usually classify an unknown object as a known one with high confidence. This over-confidence is mainly due to the fact that local part information in 3D shapes provides the main evidence for known class recognition, which nevertheless leads to the incorrect recognition of unknown classes that have similar local parts but arranged very differently. To address this problem, we propose PartCom, a 3D OSR method that calls attention to not only part information but also the part composition that is unique to each class. PartCom uses a part codebook to learn the different parts across object classes, and represents part composition as a latent distribution over the codebook. In this way, both known classes and unknown classes are cast into the space of learned parts, but known classes have composites largely distinguished from unknown ones, which enables OSR. To learn the part codebook, we formulate two necessary constraints to ensure the part codebook encodes diverse parts of different classes compactly and efficiently. In addition, we propose an optional augmenting module of Part-aware Unknown feaTure Synthesis, that further reduces open-set misclassification risks by synthesizing novel part compositions to be regarded as unknown classes. This synthesis is simply achieved by mixing part codes of different classes; training with such augmented data makes classifiers’ decision boundaries more closely fit the known classes and therefore improves open-set recognition. To evaluate the proposed method, we construct four 3D OSR tasks based on datasets of CAD shapes, multi-view scanned shapes, and LiDAR scanned shapes. Extensive experiments show that our method achieves significantly superior results than SOTA baselines on all tasks.
期刊介绍:
The International Journal of Computer Vision (IJCV) serves as a platform for sharing new research findings in the rapidly growing field of computer vision. It publishes 12 issues annually and presents high-quality, original contributions to the science and engineering of computer vision. The journal encompasses various types of articles to cater to different research outputs.
Regular articles, which span up to 25 journal pages, focus on significant technical advancements that are of broad interest to the field. These articles showcase substantial progress in computer vision.
Short articles, limited to 10 pages, offer a swift publication path for novel research outcomes. They provide a quicker means for sharing new findings with the computer vision community.
Survey articles, comprising up to 30 pages, offer critical evaluations of the current state of the art in computer vision or offer tutorial presentations of relevant topics. These articles provide comprehensive and insightful overviews of specific subject areas.
In addition to technical articles, the journal also includes book reviews, position papers, and editorials by prominent scientific figures. These contributions serve to complement the technical content and provide valuable perspectives.
The journal encourages authors to include supplementary material online, such as images, video sequences, data sets, and software. This additional material enhances the understanding and reproducibility of the published research.
Overall, the International Journal of Computer Vision is a comprehensive publication that caters to researchers in this rapidly growing field. It covers a range of article types, offers additional online resources, and facilitates the dissemination of impactful research.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
