Troels Andreasen , Gloria Bordogna , Guy De Tré , Janusz Kacprzyk , Henrik Legind Larsen , Sławomir Zadrożny
{"title":"The power and potentials of Flexible Query Answering Systems: A critical and comprehensive analysis","authors":"Troels Andreasen , Gloria Bordogna , Guy De Tré , Janusz Kacprzyk , Henrik Legind Larsen , Sławomir Zadrożny","doi":"10.1016/j.datak.2023.102246","DOIUrl":null,"url":null,"abstract":"<div><p>The popularity of chatbots, such as ChatGPT, has brought research attention to question answering systems, capable to generate natural language answers to user’s natural language queries. However, also in other kinds of systems, flexibility of querying, including but also going beyond the use of natural language, is an important feature. With this consideration in mind the paper presents a critical and comprehensive analysis of recent developments, trends and challenges of Flexible Query Answering Systems (FQASs). Flexible query answering is a multidisciplinary research field that is not limited to question answering in natural language, but comprises other query forms and interaction modalities, which aim to provide powerful means and techniques for better reflecting human preferences and intentions to retrieve relevant information. It adopts methods at the crossroad of several disciplines among which Information Retrieval (IR), databases, knowledge based systems, knowledge and data engineering, Natural Language Processing (NLP) and the semantic web may be mentioned. The analysis principles are inspired by the Preferred Reporting Items for Systematic Reviews and Meta-Analysis (PRISMA) framework, characterized by a top-down process, starting with relevant keywords for the topic of interest to retrieve relevant articles from meta-sources And complementing these articles with other relevant articles from seed sources Identified by a bottom-up process. to mine the retrieved publication data a network analysis is performed Which allows to present in a synthetic way intrinsic topics of the selected publications. issues dealt with are related to query answering methods Both model-based and data-driven (the latter based on either machine learning or deep learning) And to their needs for explainability and fairness to deal with big data Notably by taking into account data veracity. conclusions point out trends and challenges to help better shaping the future of the FQAS field.</p></div>","PeriodicalId":55184,"journal":{"name":"Data & Knowledge Engineering","volume":"149 ","pages":"Article 102246"},"PeriodicalIF":2.7000,"publicationDate":"2023-11-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.sciencedirect.com/science/article/pii/S0169023X23001064/pdfft?md5=a520b95a7109e1b8dddc31cb9594841b&pid=1-s2.0-S0169023X23001064-main.pdf","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Data & Knowledge Engineering","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0169023X23001064","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
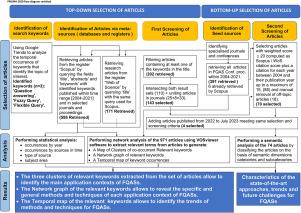
The popularity of chatbots, such as ChatGPT, has brought research attention to question answering systems, capable to generate natural language answers to user’s natural language queries. However, also in other kinds of systems, flexibility of querying, including but also going beyond the use of natural language, is an important feature. With this consideration in mind the paper presents a critical and comprehensive analysis of recent developments, trends and challenges of Flexible Query Answering Systems (FQASs). Flexible query answering is a multidisciplinary research field that is not limited to question answering in natural language, but comprises other query forms and interaction modalities, which aim to provide powerful means and techniques for better reflecting human preferences and intentions to retrieve relevant information. It adopts methods at the crossroad of several disciplines among which Information Retrieval (IR), databases, knowledge based systems, knowledge and data engineering, Natural Language Processing (NLP) and the semantic web may be mentioned. The analysis principles are inspired by the Preferred Reporting Items for Systematic Reviews and Meta-Analysis (PRISMA) framework, characterized by a top-down process, starting with relevant keywords for the topic of interest to retrieve relevant articles from meta-sources And complementing these articles with other relevant articles from seed sources Identified by a bottom-up process. to mine the retrieved publication data a network analysis is performed Which allows to present in a synthetic way intrinsic topics of the selected publications. issues dealt with are related to query answering methods Both model-based and data-driven (the latter based on either machine learning or deep learning) And to their needs for explainability and fairness to deal with big data Notably by taking into account data veracity. conclusions point out trends and challenges to help better shaping the future of the FQAS field.
期刊介绍:
Data & Knowledge Engineering (DKE) stimulates the exchange of ideas and interaction between these two related fields of interest. DKE reaches a world-wide audience of researchers, designers, managers and users. The major aim of the journal is to identify, investigate and analyze the underlying principles in the design and effective use of these systems.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
