{"title":"Zeroth- and first-order difference discrimination for unsupervised domain adaptation","authors":"Jie Wang, Xing Chen, Xiao-Lei Zhang","doi":"10.1007/s40747-023-01283-1","DOIUrl":null,"url":null,"abstract":"<p>Unsupervised domain adaptation transfers empirical knowledge from a label-rich source domain to a fully unlabeled target domain with a different distribution. A core idea of many existing approaches is to reduce the distribution divergence between domains. However, they focused only on part of the discrimination, which can be categorized into optimizing the following four objectives: reducing the intraclass distance between domains, enlarging the interclass distances between domains, reducing the intraclass distances within domains, and enlarging the interclass distances within domains. Moreover, because few methods consider multiple types of objectives, the consistency of data representations produced by different types of objectives has not yet been studied. In this paper, to address the above issues, we propose a zeroth- and first-order difference discrimination (ZFOD) approach for unsupervised domain adaptation. It first optimizes the above four objectives simultaneously. To improve the discrimination consistency of the data across the two domains, we propose a first-order difference constraint to align the interclass differences across domains. Because the proposed method needs pseudolabels for the target domain, we adopt a recent pseudolabel generation method to alleviate the negative impact of imprecise pseudolabels. We conducted an extensive comparison with nine representative conventional methods and seven remarkable deep learning-based methods on four benchmark datasets. Experimental results demonstrate that the proposed method, as a conventional approach, not only significantly outperforms the nine conventional comparison methods but is also competitive with the seven deep learning-based comparison methods. In particular, our method achieves an accuracy of 93.4% on the Office+Caltech10 dataset, which outperforms the other comparison methods. An ablation study further demonstrates the effectiveness of the proposed constraint in aligning the objectives.</p>","PeriodicalId":10524,"journal":{"name":"Complex & Intelligent Systems","volume":" 3","pages":""},"PeriodicalIF":4.6000,"publicationDate":"2023-12-05","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Complex & Intelligent Systems","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s40747-023-01283-1","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
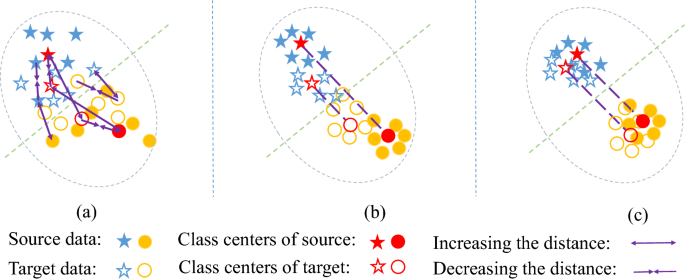
Unsupervised domain adaptation transfers empirical knowledge from a label-rich source domain to a fully unlabeled target domain with a different distribution. A core idea of many existing approaches is to reduce the distribution divergence between domains. However, they focused only on part of the discrimination, which can be categorized into optimizing the following four objectives: reducing the intraclass distance between domains, enlarging the interclass distances between domains, reducing the intraclass distances within domains, and enlarging the interclass distances within domains. Moreover, because few methods consider multiple types of objectives, the consistency of data representations produced by different types of objectives has not yet been studied. In this paper, to address the above issues, we propose a zeroth- and first-order difference discrimination (ZFOD) approach for unsupervised domain adaptation. It first optimizes the above four objectives simultaneously. To improve the discrimination consistency of the data across the two domains, we propose a first-order difference constraint to align the interclass differences across domains. Because the proposed method needs pseudolabels for the target domain, we adopt a recent pseudolabel generation method to alleviate the negative impact of imprecise pseudolabels. We conducted an extensive comparison with nine representative conventional methods and seven remarkable deep learning-based methods on four benchmark datasets. Experimental results demonstrate that the proposed method, as a conventional approach, not only significantly outperforms the nine conventional comparison methods but is also competitive with the seven deep learning-based comparison methods. In particular, our method achieves an accuracy of 93.4% on the Office+Caltech10 dataset, which outperforms the other comparison methods. An ablation study further demonstrates the effectiveness of the proposed constraint in aligning the objectives.
期刊介绍:
Complex & Intelligent Systems aims to provide a forum for presenting and discussing novel approaches, tools and techniques meant for attaining a cross-fertilization between the broad fields of complex systems, computational simulation, and intelligent analytics and visualization. The transdisciplinary research that the journal focuses on will expand the boundaries of our understanding by investigating the principles and processes that underlie many of the most profound problems facing society today.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
