Zadia Codabux, Kazi Zakia Sultana, Md Naseef-Ur-Rahman Chowdhury
{"title":"A catalog of metrics at source code level for vulnerability prediction: A systematic mapping study","authors":"Zadia Codabux, Kazi Zakia Sultana, Md Naseef-Ur-Rahman Chowdhury","doi":"10.1002/smr.2639","DOIUrl":null,"url":null,"abstract":"<p>Industry practitioners assess software from a security perspective to reduce the risks of deploying vulnerable software. Besides following security best practice guidelines during the software development life cycle, predicting vulnerability before roll-out is crucial. Software metrics are popular inputs for vulnerability prediction models. The objective of this study is to provide a comprehensive review of the source code-level security metrics presented in the literature. Our systematic mapping study started with 1451 studies obtained by searching the four digital libraries from ACM, IEEE, ScienceDirect, and Springer. After applying our inclusion/exclusion criteria as well as the snowballing technique, we narrowed down 28 studies for an in-depth study to answer four research questions pertaining to our goal. We extracted a total of 685 code-level metrics. For each study, we identified the empirical methods, quality measures, types of vulnerabilities of the prediction models, and shortcomings of the work. We found that standard machine learning models, such as decision trees, regressions, and random forests, are most frequently used for vulnerability prediction. The most common quality measures are precision, recall, accuracy, and \n<span></span><math>\n <mi>F</mi></math>-measure. Based on our findings, we conclude that the list of software metrics for measuring code-level security is not universal or generic yet. Nonetheless, the results of our study can be used as a starting point for future studies aiming at improving existing security prediction models and a catalog of metrics for vulnerability prediction for software practitioners.</p>","PeriodicalId":48898,"journal":{"name":"Journal of Software-Evolution and Process","volume":"36 7","pages":""},"PeriodicalIF":1.8000,"publicationDate":"2023-11-17","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Software-Evolution and Process","FirstCategoryId":"94","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/smr.2639","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
引用次数: 0
Abstract
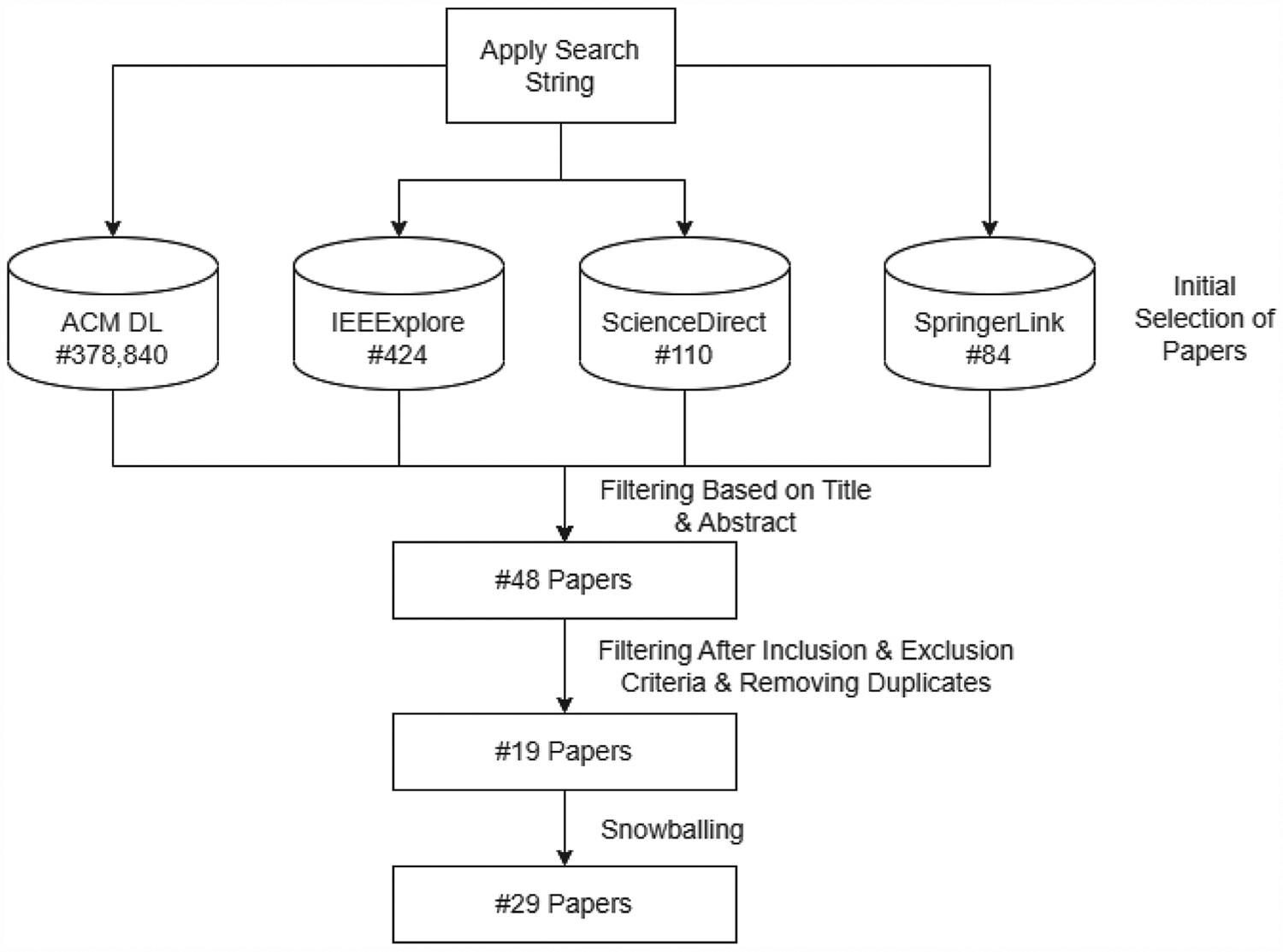
Industry practitioners assess software from a security perspective to reduce the risks of deploying vulnerable software. Besides following security best practice guidelines during the software development life cycle, predicting vulnerability before roll-out is crucial. Software metrics are popular inputs for vulnerability prediction models. The objective of this study is to provide a comprehensive review of the source code-level security metrics presented in the literature. Our systematic mapping study started with 1451 studies obtained by searching the four digital libraries from ACM, IEEE, ScienceDirect, and Springer. After applying our inclusion/exclusion criteria as well as the snowballing technique, we narrowed down 28 studies for an in-depth study to answer four research questions pertaining to our goal. We extracted a total of 685 code-level metrics. For each study, we identified the empirical methods, quality measures, types of vulnerabilities of the prediction models, and shortcomings of the work. We found that standard machine learning models, such as decision trees, regressions, and random forests, are most frequently used for vulnerability prediction. The most common quality measures are precision, recall, accuracy, and
-measure. Based on our findings, we conclude that the list of software metrics for measuring code-level security is not universal or generic yet. Nonetheless, the results of our study can be used as a starting point for future studies aiming at improving existing security prediction models and a catalog of metrics for vulnerability prediction for software practitioners.
行业从业者从安全角度评估软件,以减少部署易受攻击软件的风险。除了在软件开发生命周期中遵循安全性最佳实践指导方针外,在推出之前预测漏洞也是至关重要的。软件度量是漏洞预测模型的常用输入。本研究的目的是对文献中提出的源代码级安全度量标准进行全面的回顾。我们的系统图谱研究从检索ACM、IEEE、ScienceDirect和Springer四个数字图书馆获得的1451项研究开始。在应用我们的纳入/排除标准以及滚雪球技术后,我们缩小了28项研究范围进行深入研究,以回答与我们的目标相关的四个研究问题。我们总共提取了685个代码级指标。对于每一项研究,我们确定了经验方法、质量度量、预测模型的脆弱性类型和工作的缺点。我们发现标准的机器学习模型,如决策树、回归和随机森林,最常用于漏洞预测。最常见的质量衡量标准是精度、召回率、准确度和F $$ F $$ -measure。根据我们的发现,我们得出结论,用于度量代码级安全性的软件度量列表还不是通用的或通用的。尽管如此,我们的研究结果可以作为未来研究的起点,旨在改进现有的安全预测模型,并为软件从业者提供漏洞预测的度量目录。



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
