Enhui Huang, Yanlei Diao, Anna Liu, Liping Peng, Luciano Di Palma
{"title":"Efficient and robust active learning methods for interactive database exploration","authors":"Enhui Huang, Yanlei Diao, Anna Liu, Liping Peng, Luciano Di Palma","doi":"10.1007/s00778-023-00816-x","DOIUrl":null,"url":null,"abstract":"<p>There is an increasing gap between fast growth of data and the limited human ability to comprehend data. Consequently, there has been a growing demand of data management tools that can bridge this gap and help the user retrieve high-value content from data more effectively. In this work, we propose an interactive data exploration system as a new database service, using an approach called “explore-by-example.” Our new system is designed to assist the user in performing highly effective data exploration while reducing the human effort in the process. We cast the explore-by-example problem in a principled “active learning” framework. However, traditional active learning suffers from two fundamental limitations: slow convergence and lack of robustness under label noise. To overcome the slow convergence and label noise problems, we bring the properties of important classes of database queries to bear on the design of new algorithms and optimizations for active learning-based database exploration. Evaluation results using real-world datasets and user interest patterns show that our new system, both in the noise-free case and in the label noise case, significantly outperforms state-of-the-art active learning techniques and data exploration systems in accuracy while achieving the desired efficiency for interactive data exploration.</p>","PeriodicalId":501532,"journal":{"name":"The VLDB Journal","volume":"18 1","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2023-11-16","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"The VLDB Journal","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s00778-023-00816-x","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
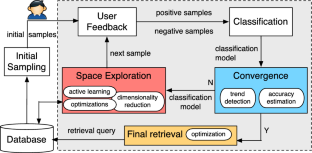
There is an increasing gap between fast growth of data and the limited human ability to comprehend data. Consequently, there has been a growing demand of data management tools that can bridge this gap and help the user retrieve high-value content from data more effectively. In this work, we propose an interactive data exploration system as a new database service, using an approach called “explore-by-example.” Our new system is designed to assist the user in performing highly effective data exploration while reducing the human effort in the process. We cast the explore-by-example problem in a principled “active learning” framework. However, traditional active learning suffers from two fundamental limitations: slow convergence and lack of robustness under label noise. To overcome the slow convergence and label noise problems, we bring the properties of important classes of database queries to bear on the design of new algorithms and optimizations for active learning-based database exploration. Evaluation results using real-world datasets and user interest patterns show that our new system, both in the noise-free case and in the label noise case, significantly outperforms state-of-the-art active learning techniques and data exploration systems in accuracy while achieving the desired efficiency for interactive data exploration.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
