{"title":"Morphtree: a polymorphic main-memory learned index for dynamic workloads","authors":"Yongping Luo, Peiquan Jin, Zhaole Chu, Xiaoliang Wang, Yigui Yuan, Zhou Zhang, Yun Luo, Xufei Wu, Peng Zou","doi":"10.1007/s00778-023-00823-y","DOIUrl":null,"url":null,"abstract":"<p>Modern database systems rely on indexes to accelerate data access. The recently proposed learned indexes can offer higher search performance with lower space costs than traditional indexes like B+-tree. We observe that existing main-memory learned indexes are particularly optimized for read-heavy workloads. However, such an optimization comes at the cost of model training and handling out-of-range key insertions, which will worsen the overall performance. We argue that workloads are not always read-heavy in real applications, and it is more important and practical to make learned indexes work efficiently for dynamic workloads with changing access patterns and data distributions. In this paper, we aim to improve the practicality of learned indexes by making them adaptive to dynamic workloads. Specifically, we propose a new polymorphic learned index named <i>Morphtree</i>, which can adaptively change the index structure to provide stable and high performance for dynamic workloads. The novelty of Morphtree lies in three aspects: (1) <i>a decoupled tree structure</i> for separating the inner search tree from the data layer consisting of leaf nodes, (2) <i>a read-optimized learned inner tree</i> for improving the performance of index search, and (3) <i>an evolving data layer</i> for automatically transforming node layouts into read friendly or write friendly according to workload changes. We evaluate these new ideas of Morphtree on various datasets and workloads. The comparative results with six up-to-date learned indexes, including ALEX, PGM-index, FITing-tree, LIPP, FINEdex, and XIndex, show that Morphtree can achieve, on average, 0.56x and 3x improvements in lookup and insertion performance, respectively. Moreover, when evaluated on dynamic workloads with changing lookup ratios and data distributions, Morphtree can achieve a sustained high throughput across different real-world datasets and query patterns, owing to its ability to automatically adjust the index structure according to workload changes.</p>","PeriodicalId":501532,"journal":{"name":"The VLDB Journal","volume":"9 1","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2023-12-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"The VLDB Journal","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s00778-023-00823-y","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
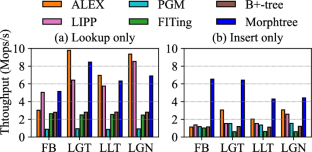
Modern database systems rely on indexes to accelerate data access. The recently proposed learned indexes can offer higher search performance with lower space costs than traditional indexes like B+-tree. We observe that existing main-memory learned indexes are particularly optimized for read-heavy workloads. However, such an optimization comes at the cost of model training and handling out-of-range key insertions, which will worsen the overall performance. We argue that workloads are not always read-heavy in real applications, and it is more important and practical to make learned indexes work efficiently for dynamic workloads with changing access patterns and data distributions. In this paper, we aim to improve the practicality of learned indexes by making them adaptive to dynamic workloads. Specifically, we propose a new polymorphic learned index named Morphtree, which can adaptively change the index structure to provide stable and high performance for dynamic workloads. The novelty of Morphtree lies in three aspects: (1) a decoupled tree structure for separating the inner search tree from the data layer consisting of leaf nodes, (2) a read-optimized learned inner tree for improving the performance of index search, and (3) an evolving data layer for automatically transforming node layouts into read friendly or write friendly according to workload changes. We evaluate these new ideas of Morphtree on various datasets and workloads. The comparative results with six up-to-date learned indexes, including ALEX, PGM-index, FITing-tree, LIPP, FINEdex, and XIndex, show that Morphtree can achieve, on average, 0.56x and 3x improvements in lookup and insertion performance, respectively. Moreover, when evaluated on dynamic workloads with changing lookup ratios and data distributions, Morphtree can achieve a sustained high throughput across different real-world datasets and query patterns, owing to its ability to automatically adjust the index structure according to workload changes.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
