{"title":"Fast Ultra High-Definition Video Deblurring via Multi-scale Separable Network","authors":"Wenqi Ren, Senyou Deng, Kaihao Zhang, Fenglong Song, Xiaochun Cao, Ming-Hsuan Yang","doi":"10.1007/s11263-023-01958-9","DOIUrl":null,"url":null,"abstract":"<p>Despite significant progress has been made in image and video deblurring, much less attention has been paid to process ultra high-definition (UHD) videos (e.g., 4K resolution). In this work, we propose a novel deep model for fast and accurate UHD video deblurring (UHDVD). The proposed UHDVD is achieved by a depth-wise separable-patch architecture, which operates with a multi-scale integration scheme to achieve a large receptive field without adding the number of generic convolutional layers and kernels. Additionally, we adopt the temporal feature attention module to effectively exploit the temporal correlation between video frames to obtain clearer recovered images. We design an asymmetrical encoder–decoder architecture with residual channel-spatial attention blocks to improve accuracy and reduce the depth of the network appropriately. Consequently, the proposed UHDVD achieves real-time performance on 4K videos at 30 fps. To train the proposed model, we build a new dataset comprised of 4K blurry videos and corresponding sharp frames using three different smartphones. Extensive experimental results show that our network performs favorably against the state-of-the-art methods on the proposed 4K dataset and existing 720p and 2K benchmarks in terms of accuracy, speed, and model size.</p>","PeriodicalId":13752,"journal":{"name":"International Journal of Computer Vision","volume":"90 1","pages":""},"PeriodicalIF":9.3000,"publicationDate":"2023-12-11","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"International Journal of Computer Vision","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s11263-023-01958-9","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
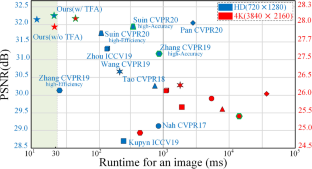
Despite significant progress has been made in image and video deblurring, much less attention has been paid to process ultra high-definition (UHD) videos (e.g., 4K resolution). In this work, we propose a novel deep model for fast and accurate UHD video deblurring (UHDVD). The proposed UHDVD is achieved by a depth-wise separable-patch architecture, which operates with a multi-scale integration scheme to achieve a large receptive field without adding the number of generic convolutional layers and kernels. Additionally, we adopt the temporal feature attention module to effectively exploit the temporal correlation between video frames to obtain clearer recovered images. We design an asymmetrical encoder–decoder architecture with residual channel-spatial attention blocks to improve accuracy and reduce the depth of the network appropriately. Consequently, the proposed UHDVD achieves real-time performance on 4K videos at 30 fps. To train the proposed model, we build a new dataset comprised of 4K blurry videos and corresponding sharp frames using three different smartphones. Extensive experimental results show that our network performs favorably against the state-of-the-art methods on the proposed 4K dataset and existing 720p and 2K benchmarks in terms of accuracy, speed, and model size.
期刊介绍:
The International Journal of Computer Vision (IJCV) serves as a platform for sharing new research findings in the rapidly growing field of computer vision. It publishes 12 issues annually and presents high-quality, original contributions to the science and engineering of computer vision. The journal encompasses various types of articles to cater to different research outputs.
Regular articles, which span up to 25 journal pages, focus on significant technical advancements that are of broad interest to the field. These articles showcase substantial progress in computer vision.
Short articles, limited to 10 pages, offer a swift publication path for novel research outcomes. They provide a quicker means for sharing new findings with the computer vision community.
Survey articles, comprising up to 30 pages, offer critical evaluations of the current state of the art in computer vision or offer tutorial presentations of relevant topics. These articles provide comprehensive and insightful overviews of specific subject areas.
In addition to technical articles, the journal also includes book reviews, position papers, and editorials by prominent scientific figures. These contributions serve to complement the technical content and provide valuable perspectives.
The journal encourages authors to include supplementary material online, such as images, video sequences, data sets, and software. This additional material enhances the understanding and reproducibility of the published research.
Overall, the International Journal of Computer Vision is a comprehensive publication that caters to researchers in this rapidly growing field. It covers a range of article types, offers additional online resources, and facilitates the dissemination of impactful research.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
