Ra’ed M. Al-Khatib, Taha Zerrouki, Mohammed M. Abu Shquier, Amar Balla
{"title":"Tashaphyne0.4: a new arabic light stemmer based on rhyzome modeling approach","authors":"Ra’ed M. Al-Khatib, Taha Zerrouki, Mohammed M. Abu Shquier, Amar Balla","doi":"10.1007/s10791-023-09429-y","DOIUrl":null,"url":null,"abstract":"<p>Stemming algorithms are crucial tools for enhancing the information retrieval process in natural language processing. This paper presents a novel Arabic light stemming algorithm called Tashaphyne0.4, the idea behind this algorithm is to extract the most precise ‘<i>roots</i>’, and ‘<i>stems</i>’ from words of an Arabic text. Thus, the proposed algorithm acts as rooter, stemmer, and segmentation tools at the same time. Our approach involves tri-fold phases (i.e., Preparation, Stems-Extractor, and Root-Extractor). Tashaphyne0.4 has shown better results than six other stemmers (i.e., Khoja, ISRI, Motaz/Light10, Tashaphyne0.3, FARASA, and Assem stemmers). The comparison is performed using four different Arabic comprehensive-benchmarks datasets. In conclusion, our proposed stemmer achieved remarkable results and outperformed other competitive stemmers in extracting ‘<i>Roots</i>’ and ‘<i>Stems</i>’.</p>","PeriodicalId":54352,"journal":{"name":"Information Retrieval Journal","volume":"18 1","pages":""},"PeriodicalIF":1.9000,"publicationDate":"2023-12-14","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Information Retrieval Journal","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10791-023-09429-y","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
引用次数: 0
Abstract
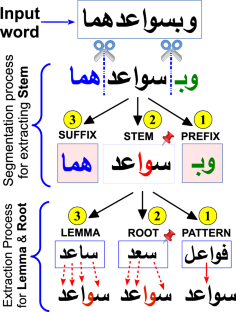
Stemming algorithms are crucial tools for enhancing the information retrieval process in natural language processing. This paper presents a novel Arabic light stemming algorithm called Tashaphyne0.4, the idea behind this algorithm is to extract the most precise ‘roots’, and ‘stems’ from words of an Arabic text. Thus, the proposed algorithm acts as rooter, stemmer, and segmentation tools at the same time. Our approach involves tri-fold phases (i.e., Preparation, Stems-Extractor, and Root-Extractor). Tashaphyne0.4 has shown better results than six other stemmers (i.e., Khoja, ISRI, Motaz/Light10, Tashaphyne0.3, FARASA, and Assem stemmers). The comparison is performed using four different Arabic comprehensive-benchmarks datasets. In conclusion, our proposed stemmer achieved remarkable results and outperformed other competitive stemmers in extracting ‘Roots’ and ‘Stems’.
期刊介绍:
The journal provides an international forum for the publication of theory, algorithms, analysis and experiments across the broad area of information retrieval. Topics of interest include search, indexing, analysis, and evaluation for applications such as the web, social and streaming media, recommender systems, and text archives. This includes research on human factors in search, bridging artificial intelligence and information retrieval, and domain-specific search applications.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
