Chunyan Zeng , Shuai Kong , Zhifeng Wang , Shixiong Feng , Nan Zhao , Juan Wang
{"title":"Deletion and insertion tampering detection for speech authentication based on fluctuating super vector of electrical network frequency","authors":"Chunyan Zeng , Shuai Kong , Zhifeng Wang , Shixiong Feng , Nan Zhao , Juan Wang","doi":"10.1016/j.specom.2024.103046","DOIUrl":null,"url":null,"abstract":"<div><p>The current digital speech deletion and insertion tampering detection methods mainly employes the extraction of phase and frequency features of the Electrical Network Frequency (ENF). However, there are some problems with the existing approaches, such as the alignment problem for speech samples with different durations, the sparsity of ENF features, and the small number of tampered speech samples for training, which lead to low accuracy of deletion and insertion tampering detection. Therefore, this paper proposes a tampering detection method for digital speech deletion and insertion based on ENF Fluctuation Super-vector (ENF-FSV) and deep feature learning representation. By extracting the parameters of ENF phase and frequency fitting curves, feature alignment and dimensionality reduction are achieved, and the alignment and sparsity problems are avoided while the fluctuation information of phase and frequency is extracted. To solve the problem of the insufficient sample size of tampered speech for training, the ENF Universal Background Model (ENF-UBM) is built by a large number of untampered speech samples, and the mean vector is updated to extract ENF-FSV. Considering the shallow representation of ENF features with not highlighting important features, we construct an end-to-end deep neural network to strengthen the attention to the abrupt fluctuation information by the attention mechanism to enhance the representational power of the ENF-FSV features, and then the deep ENF-FSV features extracted by the Residual Network (ResNet) module are fed to the designed classification network for tampering detection. The experimental results show that the method in this paper exhibits higher accuracy and better robustness in the Carioca, New Spanish, and ENF High-sampling Group (ENF-HG) databases when compared with the state-of-the-art methods.</p></div>","PeriodicalId":49485,"journal":{"name":"Speech Communication","volume":"158 ","pages":"Article 103046"},"PeriodicalIF":3.0000,"publicationDate":"2024-03-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Speech Communication","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0167639324000189","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/2/12 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"ACOUSTICS","Score":null,"Total":0}
引用次数: 0
Abstract
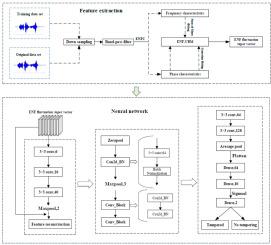
The current digital speech deletion and insertion tampering detection methods mainly employes the extraction of phase and frequency features of the Electrical Network Frequency (ENF). However, there are some problems with the existing approaches, such as the alignment problem for speech samples with different durations, the sparsity of ENF features, and the small number of tampered speech samples for training, which lead to low accuracy of deletion and insertion tampering detection. Therefore, this paper proposes a tampering detection method for digital speech deletion and insertion based on ENF Fluctuation Super-vector (ENF-FSV) and deep feature learning representation. By extracting the parameters of ENF phase and frequency fitting curves, feature alignment and dimensionality reduction are achieved, and the alignment and sparsity problems are avoided while the fluctuation information of phase and frequency is extracted. To solve the problem of the insufficient sample size of tampered speech for training, the ENF Universal Background Model (ENF-UBM) is built by a large number of untampered speech samples, and the mean vector is updated to extract ENF-FSV. Considering the shallow representation of ENF features with not highlighting important features, we construct an end-to-end deep neural network to strengthen the attention to the abrupt fluctuation information by the attention mechanism to enhance the representational power of the ENF-FSV features, and then the deep ENF-FSV features extracted by the Residual Network (ResNet) module are fed to the designed classification network for tampering detection. The experimental results show that the method in this paper exhibits higher accuracy and better robustness in the Carioca, New Spanish, and ENF High-sampling Group (ENF-HG) databases when compared with the state-of-the-art methods.
期刊介绍:
Speech Communication is an interdisciplinary journal whose primary objective is to fulfil the need for the rapid dissemination and thorough discussion of basic and applied research results.
The journal''s primary objectives are:
• to present a forum for the advancement of human and human-machine speech communication science;
• to stimulate cross-fertilization between different fields of this domain;
• to contribute towards the rapid and wide diffusion of scientifically sound contributions in this domain.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
