François Delon, Gabriel Bédubourg, Léo Bouscarrat, Jean-Baptiste Meynard, Aude Valois, Benjamin Queyriaux, Carlos Ramisch, Marc Tanti
{"title":"Infectious risk events and their novelty in event-based surveillance: new definitions and annotated corpus","authors":"François Delon, Gabriel Bédubourg, Léo Bouscarrat, Jean-Baptiste Meynard, Aude Valois, Benjamin Queyriaux, Carlos Ramisch, Marc Tanti","doi":"10.1007/s10579-024-09728-w","DOIUrl":null,"url":null,"abstract":"<p> Event-based surveillance (EBS) requires the analysis of an ever-increasing volume of documents, requiring automated processing to support human analysts. Few annotated corpora are available for the evaluation of information extraction tools in the EBS domain. The main objective of this work was to build a corpus containing documents which are representative of those collected in the current EBS information systems, and to annotate them with events and their novelty. We proposed new definitions of infectious events and their novelty suited to the background work of analysts working in the EBS domain, and we compiled a corpus of 305 documents describing 283 infectious events. There were 36 included documents in French, representing a total of 11 events, with the remainder in English. We annotated novelty for the 110 most recent documents in the corpus, resulting in 101 events. The inter-annotator agreement was 0.74 for event identification (F1-Score) and 0.69 [95% CI: 0.51; 0.88] (Kappa) for novelty annotation. The overall agreement for entity annotation was lower, with a significant variation according to the type of entities considered (range 0.30–0.68). This corpus is a useful tool for creating and evaluating algorithms and methods submitted by EBS research teams for event detection and annotation of their novelties, aiming at the operational improvement of document flow processing. The small size of this corpus makes it less suitable for training natural language processing models, although this limitation tends to fade away when using few-shots learning methods.\n</p>","PeriodicalId":49927,"journal":{"name":"Language Resources and Evaluation","volume":"116 1","pages":""},"PeriodicalIF":1.8000,"publicationDate":"2024-03-05","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Language Resources and Evaluation","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10579-024-09728-w","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
引用次数: 0
Abstract
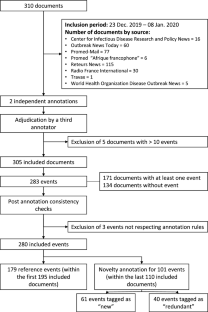
Event-based surveillance (EBS) requires the analysis of an ever-increasing volume of documents, requiring automated processing to support human analysts. Few annotated corpora are available for the evaluation of information extraction tools in the EBS domain. The main objective of this work was to build a corpus containing documents which are representative of those collected in the current EBS information systems, and to annotate them with events and their novelty. We proposed new definitions of infectious events and their novelty suited to the background work of analysts working in the EBS domain, and we compiled a corpus of 305 documents describing 283 infectious events. There were 36 included documents in French, representing a total of 11 events, with the remainder in English. We annotated novelty for the 110 most recent documents in the corpus, resulting in 101 events. The inter-annotator agreement was 0.74 for event identification (F1-Score) and 0.69 [95% CI: 0.51; 0.88] (Kappa) for novelty annotation. The overall agreement for entity annotation was lower, with a significant variation according to the type of entities considered (range 0.30–0.68). This corpus is a useful tool for creating and evaluating algorithms and methods submitted by EBS research teams for event detection and annotation of their novelties, aiming at the operational improvement of document flow processing. The small size of this corpus makes it less suitable for training natural language processing models, although this limitation tends to fade away when using few-shots learning methods.
期刊介绍:
Language Resources and Evaluation is the first publication devoted to the acquisition, creation, annotation, and use of language resources, together with methods for evaluation of resources, technologies, and applications.
Language resources include language data and descriptions in machine readable form used to assist and augment language processing applications, such as written or spoken corpora and lexica, multimodal resources, grammars, terminology or domain specific databases and dictionaries, ontologies, multimedia databases, etc., as well as basic software tools for their acquisition, preparation, annotation, management, customization, and use.
Evaluation of language resources concerns assessing the state-of-the-art for a given technology, comparing different approaches to a given problem, assessing the availability of resources and technologies for a given application, benchmarking, and assessing system usability and user satisfaction.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
