{"title":"ParTRE: A relational triple extraction model of complicated entities and imbalanced relations in Parkinson’s disease","authors":"Xiaoming Zhang , Can Yu , Rui Yan","doi":"10.1016/j.jbi.2024.104624","DOIUrl":null,"url":null,"abstract":"<div><p>The relational triple extraction of unstructured medical texts about Parkinson’s disease is critical for the construction of a medical knowledge graph. However, the triple entities in Parkinson’s disease are usually complicated and overlapped, which impedes the accuracy of triple extraction, especially in the case of rarely available corpus. Therefore, this study first builds a corpus about Parkinson’s disease. Then, a tagging-based three-stage relational triple extraction model is proposed, named ParTRE. To enhance the contextual representation of sentences, the proposed model employs BiLSTM modules to capture fine-grained semantic information. Additionally, a conditional normalization layer is used so that entity pairs can be extracted accurately from two complementary directions. As for the imbalanced relationship categories, an adaptive loss function strategy based on focal loss is derived by assigning different weights to relationship categories and reducing the loss of easy-to-classify samples. The model performance is evaluated on the Parkinson’s corpus and public datasets. The results indicate that the proposed model achieves an overall F1-score of 93.3 % on the Parkinson’s corpus and comparable performance on public datasets compared with the state-of-the-art methods. Moreover, a satisfactory result is achieved by the proposed model on conquering the overlapped entities and imbalanced relationship categories. Owing to demonstrated availability and validity, the proposed method can be integrated with medical knowledge graphs and therefore benefits medical intelligence.</p></div>","PeriodicalId":15263,"journal":{"name":"Journal of Biomedical Informatics","volume":"152 ","pages":"Article 104624"},"PeriodicalIF":4.5000,"publicationDate":"2024-03-11","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Biomedical Informatics","FirstCategoryId":"3","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S153204642400042X","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
引用次数: 0
Abstract
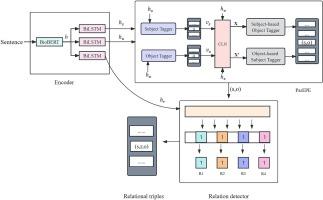
The relational triple extraction of unstructured medical texts about Parkinson’s disease is critical for the construction of a medical knowledge graph. However, the triple entities in Parkinson’s disease are usually complicated and overlapped, which impedes the accuracy of triple extraction, especially in the case of rarely available corpus. Therefore, this study first builds a corpus about Parkinson’s disease. Then, a tagging-based three-stage relational triple extraction model is proposed, named ParTRE. To enhance the contextual representation of sentences, the proposed model employs BiLSTM modules to capture fine-grained semantic information. Additionally, a conditional normalization layer is used so that entity pairs can be extracted accurately from two complementary directions. As for the imbalanced relationship categories, an adaptive loss function strategy based on focal loss is derived by assigning different weights to relationship categories and reducing the loss of easy-to-classify samples. The model performance is evaluated on the Parkinson’s corpus and public datasets. The results indicate that the proposed model achieves an overall F1-score of 93.3 % on the Parkinson’s corpus and comparable performance on public datasets compared with the state-of-the-art methods. Moreover, a satisfactory result is achieved by the proposed model on conquering the overlapped entities and imbalanced relationship categories. Owing to demonstrated availability and validity, the proposed method can be integrated with medical knowledge graphs and therefore benefits medical intelligence.
期刊介绍:
The Journal of Biomedical Informatics reflects a commitment to high-quality original research papers, reviews, and commentaries in the area of biomedical informatics methodology. Although we publish articles motivated by applications in the biomedical sciences (for example, clinical medicine, health care, population health, and translational bioinformatics), the journal emphasizes reports of new methodologies and techniques that have general applicability and that form the basis for the evolving science of biomedical informatics. Articles on medical devices; evaluations of implemented systems (including clinical trials of information technologies); or papers that provide insight into a biological process, a specific disease, or treatment options would generally be more suitable for publication in other venues. Papers on applications of signal processing and image analysis are often more suitable for biomedical engineering journals or other informatics journals, although we do publish papers that emphasize the information management and knowledge representation/modeling issues that arise in the storage and use of biological signals and images. System descriptions are welcome if they illustrate and substantiate the underlying methodology that is the principal focus of the report and an effort is made to address the generalizability and/or range of application of that methodology. Note also that, given the international nature of JBI, papers that deal with specific languages other than English, or with country-specific health systems or approaches, are acceptable for JBI only if they offer generalizable lessons that are relevant to the broad JBI readership, regardless of their country, language, culture, or health system.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
