Muhamet Kastrati, Zenun Kastrati, Ali Shariq Imran, Marenglen Biba
{"title":"Leveraging distant supervision and deep learning for twitter sentiment and emotion classification","authors":"Muhamet Kastrati, Zenun Kastrati, Ali Shariq Imran, Marenglen Biba","doi":"10.1007/s10844-024-00845-0","DOIUrl":null,"url":null,"abstract":"<p>Nowadays, various applications across industries, healthcare, and security have begun adopting automatic sentiment analysis and emotion detection in short texts, such as posts from social media. Twitter stands out as one of the most popular online social media platforms due to its easy, unique, and advanced accessibility using the API. On the other hand, supervised learning is the most widely used paradigm for tasks involving sentiment polarity and fine-grained emotion detection in short and informal texts, such as Twitter posts. However, supervised learning models are data-hungry and heavily reliant on abundant labeled data, which remains a challenge. This study aims to address this challenge by creating a large-scale real-world dataset of 17.5 million tweets. A distant supervision approach relying on emojis available in tweets is applied to label tweets corresponding to Ekman’s six basic emotions. Additionally, we conducted a series of experiments using various conventional machine learning models and deep learning, including transformer-based models, on our dataset to establish baseline results. The experimental results and an extensive ablation analysis on the dataset showed that BiLSTM with FastText and an attention mechanism outperforms other models in both classification tasks, achieving an F1-score of 70.92% for sentiment classification and 54.85% for emotion detection.</p>","PeriodicalId":56119,"journal":{"name":"Journal of Intelligent Information Systems","volume":"77 1","pages":""},"PeriodicalIF":3.4000,"publicationDate":"2024-03-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Intelligent Information Systems","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10844-024-00845-0","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
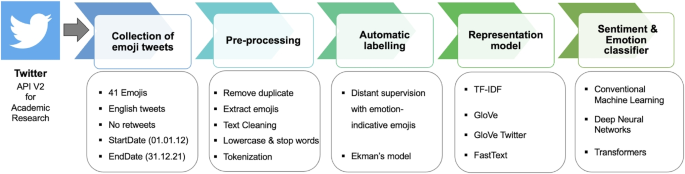
Nowadays, various applications across industries, healthcare, and security have begun adopting automatic sentiment analysis and emotion detection in short texts, such as posts from social media. Twitter stands out as one of the most popular online social media platforms due to its easy, unique, and advanced accessibility using the API. On the other hand, supervised learning is the most widely used paradigm for tasks involving sentiment polarity and fine-grained emotion detection in short and informal texts, such as Twitter posts. However, supervised learning models are data-hungry and heavily reliant on abundant labeled data, which remains a challenge. This study aims to address this challenge by creating a large-scale real-world dataset of 17.5 million tweets. A distant supervision approach relying on emojis available in tweets is applied to label tweets corresponding to Ekman’s six basic emotions. Additionally, we conducted a series of experiments using various conventional machine learning models and deep learning, including transformer-based models, on our dataset to establish baseline results. The experimental results and an extensive ablation analysis on the dataset showed that BiLSTM with FastText and an attention mechanism outperforms other models in both classification tasks, achieving an F1-score of 70.92% for sentiment classification and 54.85% for emotion detection.
期刊介绍:
The mission of the Journal of Intelligent Information Systems: Integrating Artifical Intelligence and Database Technologies is to foster and present research and development results focused on the integration of artificial intelligence and database technologies to create next generation information systems - Intelligent Information Systems.
These new information systems embody knowledge that allows them to exhibit intelligent behavior, cooperate with users and other systems in problem solving, discovery, access, retrieval and manipulation of a wide variety of multimedia data and knowledge, and reason under uncertainty. Increasingly, knowledge-directed inference processes are being used to:
discover knowledge from large data collections,
provide cooperative support to users in complex query formulation and refinement,
access, retrieve, store and manage large collections of multimedia data and knowledge,
integrate information from multiple heterogeneous data and knowledge sources, and
reason about information under uncertain conditions.
Multimedia and hypermedia information systems now operate on a global scale over the Internet, and new tools and techniques are needed to manage these dynamic and evolving information spaces.
The Journal of Intelligent Information Systems provides a forum wherein academics, researchers and practitioners may publish high-quality, original and state-of-the-art papers describing theoretical aspects, systems architectures, analysis and design tools and techniques, and implementation experiences in intelligent information systems. The categories of papers published by JIIS include: research papers, invited papters, meetings, workshop and conference annoucements and reports, survey and tutorial articles, and book reviews. Short articles describing open problems or their solutions are also welcome.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
