{"title":"Cross-Project Defect Prediction Using Transfer Learning with Long Short-Term Memory Networks","authors":"Hongwei Tao, Lianyou Fu, Qiaoling Cao, Xiaoxu Niu, Haoran Chen, Songtao Shang, Yang Xian","doi":"10.1049/2024/5550801","DOIUrl":null,"url":null,"abstract":"<p>With the increasing number of software projects, within-project defect prediction (WPDP) has already been unable to meet the demand, and cross-project defect prediction (CPDP) is playing an increasingly significant role in the area of software engineering. The classic CPDP methods mainly concentrated on applying metric features to predict defects. However, these approaches failed to consider the rich semantic information, which usually contains the relationship between software defects and context. Since traditional methods are unable to exploit this characteristic, their performance is often unsatisfactory. In this paper, a transfer long short-term memory (TLSTM) network model is first proposed. Transfer semantic features are extracted by adding a transfer learning algorithm to the long short-term memory (LSTM) network. Then, the traditional metric features and semantic features are combined for CPDP. First, the abstract syntax trees (AST) are generated based on the source codes. Second, the AST node contents are converted into integer vectors as inputs to the TLSTM model. Then, the semantic features of the program can be extracted by TLSTM. On the other hand, transferable metric features are extracted by transfer component analysis (TCA). Finally, the semantic features and metric features are combined and input into the logical regression (LR) classifier for training. The presented TLSTM model performs better on the <i>f</i>-measure indicator than other machine and deep learning models, according to the outcomes of several open-source projects of the PROMISE repository. The TLSTM model built with a single feature achieves 0.7% and 2.1% improvement on Log4j-1.2 and Xalan-2.7, respectively. When using combined features to train the prediction model, we call this model a transfer long short-term memory for defect prediction (DPTLSTM). DPTLSTM achieves a 2.9% and 5% improvement on Synapse-1.2 and Xerces-1.4.4, respectively. Both prove the superiority of the proposed model on the CPDP task. This is because LSTM capture long-term dependencies in sequence data and extract features that contain source code structure and context information. It can be concluded that: (1) the TLSTM model has the advantage of preserving information, which can better retain the semantic features related to software defects; (2) compared with the CPDP model trained with traditional metric features, the performance of the model can validly enhance by combining semantic features and metric features.</p>","PeriodicalId":50378,"journal":{"name":"IET Software","volume":"2024 1","pages":""},"PeriodicalIF":1.3000,"publicationDate":"2024-03-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1049/2024/5550801","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"IET Software","FirstCategoryId":"94","ListUrlMain":"https://ietresearch.onlinelibrary.wiley.com/doi/10.1049/2024/5550801","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
引用次数: 0
Abstract
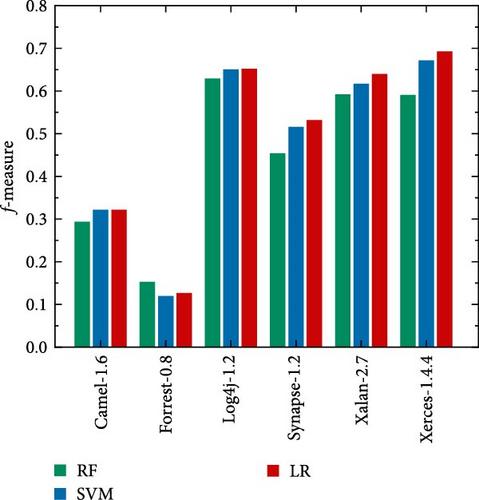
With the increasing number of software projects, within-project defect prediction (WPDP) has already been unable to meet the demand, and cross-project defect prediction (CPDP) is playing an increasingly significant role in the area of software engineering. The classic CPDP methods mainly concentrated on applying metric features to predict defects. However, these approaches failed to consider the rich semantic information, which usually contains the relationship between software defects and context. Since traditional methods are unable to exploit this characteristic, their performance is often unsatisfactory. In this paper, a transfer long short-term memory (TLSTM) network model is first proposed. Transfer semantic features are extracted by adding a transfer learning algorithm to the long short-term memory (LSTM) network. Then, the traditional metric features and semantic features are combined for CPDP. First, the abstract syntax trees (AST) are generated based on the source codes. Second, the AST node contents are converted into integer vectors as inputs to the TLSTM model. Then, the semantic features of the program can be extracted by TLSTM. On the other hand, transferable metric features are extracted by transfer component analysis (TCA). Finally, the semantic features and metric features are combined and input into the logical regression (LR) classifier for training. The presented TLSTM model performs better on the f-measure indicator than other machine and deep learning models, according to the outcomes of several open-source projects of the PROMISE repository. The TLSTM model built with a single feature achieves 0.7% and 2.1% improvement on Log4j-1.2 and Xalan-2.7, respectively. When using combined features to train the prediction model, we call this model a transfer long short-term memory for defect prediction (DPTLSTM). DPTLSTM achieves a 2.9% and 5% improvement on Synapse-1.2 and Xerces-1.4.4, respectively. Both prove the superiority of the proposed model on the CPDP task. This is because LSTM capture long-term dependencies in sequence data and extract features that contain source code structure and context information. It can be concluded that: (1) the TLSTM model has the advantage of preserving information, which can better retain the semantic features related to software defects; (2) compared with the CPDP model trained with traditional metric features, the performance of the model can validly enhance by combining semantic features and metric features.
期刊介绍:
IET Software publishes papers on all aspects of the software lifecycle, including design, development, implementation and maintenance. The focus of the journal is on the methods used to develop and maintain software, and their practical application.
Authors are especially encouraged to submit papers on the following topics, although papers on all aspects of software engineering are welcome:
Software and systems requirements engineering
Formal methods, design methods, practice and experience
Software architecture, aspect and object orientation, reuse and re-engineering
Testing, verification and validation techniques
Software dependability and measurement
Human systems engineering and human-computer interaction
Knowledge engineering; expert and knowledge-based systems, intelligent agents
Information systems engineering
Application of software engineering in industry and commerce
Software engineering technology transfer
Management of software development
Theoretical aspects of software development
Machine learning
Big data and big code
Cloud computing
Current Special Issue. Call for papers:
Knowledge Discovery for Software Development - https://digital-library.theiet.org/files/IET_SEN_CFP_KDSD.pdf
Big Data Analytics for Sustainable Software Development - https://digital-library.theiet.org/files/IET_SEN_CFP_BDASSD.pdf




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
