{"title":"Unmasking the sky: high-resolution PM2.5 prediction in Texas using machine learning techniques","authors":"Kai Zhang, Jeffrey Lin, Yuanfei Li, Yue Sun, Weitian Tong, Fangyu Li, Lung-Chang Chien, Yiping Yang, Wei-Chung Su, Hezhong Tian, Peng Fu, Fengxiang Qiao, Xiaobo Xue Romeiko, Shao Lin, Sheng Luo, Elena Craft","doi":"10.1038/s41370-024-00659-w","DOIUrl":null,"url":null,"abstract":"Although PM2.5 (fine particulate matter with an aerodynamic diameter less than 2.5 µm) is an air pollutant of great concern in Texas, limited regulatory monitors pose a significant challenge for decision-making and environmental studies. This study aimed to predict PM2.5 concentrations at a fine spatial scale on a daily basis by using novel machine learning approaches and incorporating satellite-derived Aerosol Optical Depth (AOD) and a variety of weather and land use variables. We compiled a comprehensive dataset in Texas from 2013 to 2017, including ground-level PM2.5 concentrations from regulatory monitors; AOD values at 1-km resolution based on images retrieved from the MODIS satellite; and weather, land-use, population density, among others. We built predictive models for each year separately to estimate PM2.5 concentrations using two machine learning approaches called gradient boosted trees and random forest. We evaluated the model prediction performance using in-sample and out-of-sample validations. Our predictive models demonstrate excellent in-sample model performance, as indicated by high R2 values generated from the gradient boosting models (0.94–0.97) and random forest models (0.81–0.90). However, the out-of-sample R2 values fall within a range of 0.52–0.75 for gradient boosting models and 0.44–0.69 for random forest models. Model performance varies slightly across years. A generally decreasing trend in predicted PM2.5 concentrations over time is observed in Eastern Texas. We utilized machine learning approaches to predict PM2.5 levels in Texas. Both gradient boosting and random forest models perform well. Gradient boosting models perform slightly better than random forest models. Our models showed excellent in-sample prediction performance (R2 > 0.9).","PeriodicalId":15684,"journal":{"name":"Journal of Exposure Science and Environmental Epidemiology","volume":"34 5","pages":"814-820"},"PeriodicalIF":4.7000,"publicationDate":"2024-04-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.nature.com/articles/s41370-024-00659-w.pdf","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Exposure Science and Environmental Epidemiology","FirstCategoryId":"3","ListUrlMain":"https://www.nature.com/articles/s41370-024-00659-w","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"ENVIRONMENTAL SCIENCES","Score":null,"Total":0}
引用次数: 0
Abstract
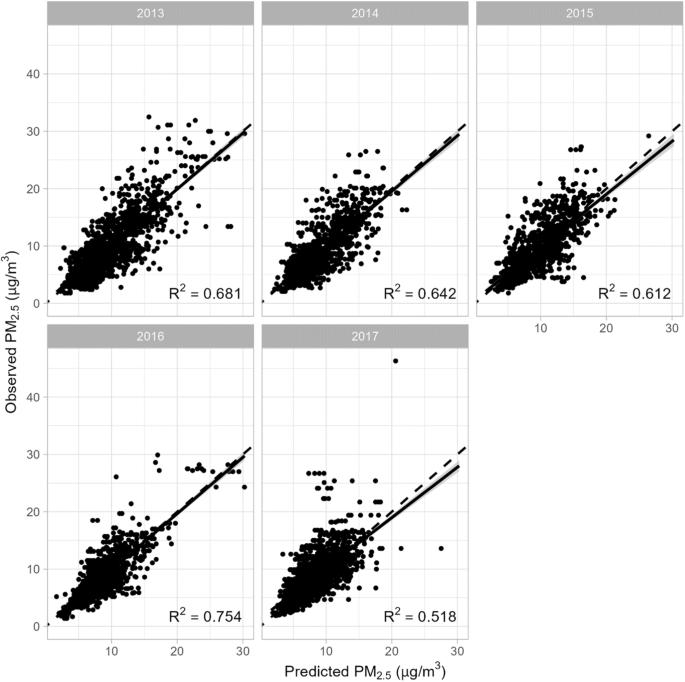
Although PM2.5 (fine particulate matter with an aerodynamic diameter less than 2.5 µm) is an air pollutant of great concern in Texas, limited regulatory monitors pose a significant challenge for decision-making and environmental studies. This study aimed to predict PM2.5 concentrations at a fine spatial scale on a daily basis by using novel machine learning approaches and incorporating satellite-derived Aerosol Optical Depth (AOD) and a variety of weather and land use variables. We compiled a comprehensive dataset in Texas from 2013 to 2017, including ground-level PM2.5 concentrations from regulatory monitors; AOD values at 1-km resolution based on images retrieved from the MODIS satellite; and weather, land-use, population density, among others. We built predictive models for each year separately to estimate PM2.5 concentrations using two machine learning approaches called gradient boosted trees and random forest. We evaluated the model prediction performance using in-sample and out-of-sample validations. Our predictive models demonstrate excellent in-sample model performance, as indicated by high R2 values generated from the gradient boosting models (0.94–0.97) and random forest models (0.81–0.90). However, the out-of-sample R2 values fall within a range of 0.52–0.75 for gradient boosting models and 0.44–0.69 for random forest models. Model performance varies slightly across years. A generally decreasing trend in predicted PM2.5 concentrations over time is observed in Eastern Texas. We utilized machine learning approaches to predict PM2.5 levels in Texas. Both gradient boosting and random forest models perform well. Gradient boosting models perform slightly better than random forest models. Our models showed excellent in-sample prediction performance (R2 > 0.9).
期刊介绍:
Journal of Exposure Science and Environmental Epidemiology (JESEE) aims to be the premier and authoritative source of information on advances in exposure science for professionals in a wide range of environmental and public health disciplines.
JESEE publishes original peer-reviewed research presenting significant advances in exposure science and exposure analysis, including development and application of the latest technologies for measuring exposures, and innovative computational approaches for translating novel data streams to characterize and predict exposures. The types of papers published in the research section of JESEE are original research articles, translation studies, and correspondence. Reported results should further understanding of the relationship between environmental exposure and human health, describe evaluated novel exposure science tools, or demonstrate potential of exposure science to enable decisions and actions that promote and protect human health.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
