Xuemiao Zhang, Zhouxing Tan, Fengyu Lu, Rui Yan, Junfei Liu
{"title":"Adaptive semi-supervised learning from stronger augmentation transformations of discrete text information","authors":"Xuemiao Zhang, Zhouxing Tan, Fengyu Lu, Rui Yan, Junfei Liu","doi":"10.1007/s10115-024-02100-y","DOIUrl":null,"url":null,"abstract":"<p>Semi-supervised learning is a promising approach to dealing with the problem of insufficient labeled data. Recent methods grouped into paradigms of consistency regularization and pseudo-labeling have outstanding performances on image data, but achieve limited improvements when employed for processing textual information, due to the neglect of the discrete nature of textual information and the lack of high-quality text augmentation transformation means. In this paper, we propose the novel SeqMatch method. It can automatically perceive abnormal model states caused by anomalous data obtained by text augmentations and reduce their interferences and instead leverages normal ones to improve the effectiveness of consistency regularization. And it generates hard artificial pseudo-labels to enable the model to be efficiently updated and optimized toward low entropy. We also design several much stronger well-organized text augmentation transformation pipelines to increase the divergence between two views of unlabeled discrete textual sequences, thus enabling the model to learn more knowledge from the alignment. Extensive comparative experimental results show that our SeqMatch outperforms previous methods on three widely used benchmarks significantly. In particular, SeqMatch can achieve a maximum performance improvement of 16.4% compared to purely supervised training when provided with a minimal number of labeled examples.</p>","PeriodicalId":54749,"journal":{"name":"Knowledge and Information Systems","volume":"35 1","pages":""},"PeriodicalIF":3.1000,"publicationDate":"2024-04-11","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Knowledge and Information Systems","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10115-024-02100-y","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
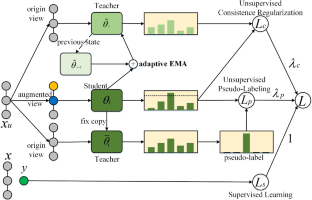
Semi-supervised learning is a promising approach to dealing with the problem of insufficient labeled data. Recent methods grouped into paradigms of consistency regularization and pseudo-labeling have outstanding performances on image data, but achieve limited improvements when employed for processing textual information, due to the neglect of the discrete nature of textual information and the lack of high-quality text augmentation transformation means. In this paper, we propose the novel SeqMatch method. It can automatically perceive abnormal model states caused by anomalous data obtained by text augmentations and reduce their interferences and instead leverages normal ones to improve the effectiveness of consistency regularization. And it generates hard artificial pseudo-labels to enable the model to be efficiently updated and optimized toward low entropy. We also design several much stronger well-organized text augmentation transformation pipelines to increase the divergence between two views of unlabeled discrete textual sequences, thus enabling the model to learn more knowledge from the alignment. Extensive comparative experimental results show that our SeqMatch outperforms previous methods on three widely used benchmarks significantly. In particular, SeqMatch can achieve a maximum performance improvement of 16.4% compared to purely supervised training when provided with a minimal number of labeled examples.
期刊介绍:
Knowledge and Information Systems (KAIS) provides an international forum for researchers and professionals to share their knowledge and report new advances on all topics related to knowledge systems and advanced information systems. This monthly peer-reviewed archival journal publishes state-of-the-art research reports on emerging topics in KAIS, reviews of important techniques in related areas, and application papers of interest to a general readership.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
