{"title":"Learning peptide properties with positive examples only","authors":"Mehrad Ansari and Andrew D. White","doi":"10.1039/D3DD00218G","DOIUrl":null,"url":null,"abstract":"<p >Deep learning can create accurate predictive models by exploiting existing large-scale experimental data, and guide the design of molecules. However, a major barrier is the requirement of both positive and negative examples in the classical supervised learning frameworks. Notably, most peptide databases come with missing information and low number of observations on negative examples, as such sequences are hard to obtain using high-throughput screening methods. To address this challenge, we solely exploit the limited known positive examples in a semi-supervised setting, and discover peptide sequences that are likely to map to certain antimicrobial properties <em>via</em> positive-unlabeled learning (PU). In particular, we use the two learning strategies of adapting base classifier and reliable negative identification to build deep learning models for inferring solubility, hemolysis, binding against SHP-2, and non-fouling activity of peptides, given their sequence. We evaluate the predictive performance of our PU learning method and show that by only using the positive data, it can achieve competitive performance when compared with the classical positive–negative (PN) classification approach, where there is access to both positive and negative examples.</p>","PeriodicalId":72816,"journal":{"name":"Digital discovery","volume":" 5","pages":" 977-986"},"PeriodicalIF":6.2000,"publicationDate":"2024-04-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://pubs.rsc.org/en/content/articlepdf/2024/dd/d3dd00218g?page=search","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Digital discovery","FirstCategoryId":"1085","ListUrlMain":"https://pubs.rsc.org/en/content/articlelanding/2024/dd/d3dd00218g","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"CHEMISTRY, MULTIDISCIPLINARY","Score":null,"Total":0}
引用次数: 0
Abstract
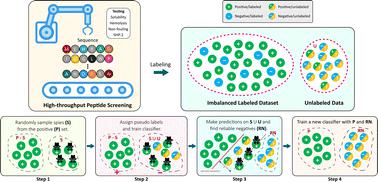
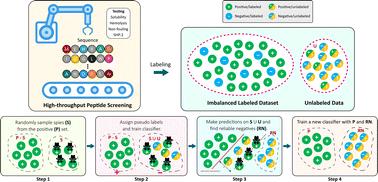
Deep learning can create accurate predictive models by exploiting existing large-scale experimental data, and guide the design of molecules. However, a major barrier is the requirement of both positive and negative examples in the classical supervised learning frameworks. Notably, most peptide databases come with missing information and low number of observations on negative examples, as such sequences are hard to obtain using high-throughput screening methods. To address this challenge, we solely exploit the limited known positive examples in a semi-supervised setting, and discover peptide sequences that are likely to map to certain antimicrobial properties via positive-unlabeled learning (PU). In particular, we use the two learning strategies of adapting base classifier and reliable negative identification to build deep learning models for inferring solubility, hemolysis, binding against SHP-2, and non-fouling activity of peptides, given their sequence. We evaluate the predictive performance of our PU learning method and show that by only using the positive data, it can achieve competitive performance when compared with the classical positive–negative (PN) classification approach, where there is access to both positive and negative examples.
深度学习可以利用现有的大规模实验数据创建精确的预测模型,并指导分子设计。然而,在经典的监督学习框架中,一个主要障碍是需要正反两方面的实例。值得注意的是,大多数肽数据库都存在信息缺失的问题,而且负面示例的观测数据较少,因为使用高通量筛选方法很难获得这类序列。为了应对这一挑战,我们在半监督设置中仅利用有限的已知正向示例,通过正向无标记学习(PU)发现可能映射到某些抗菌特性的肽序列。特别是,我们使用适应基础分类器和可靠的负识别这两种学习策略来建立深度学习模型,以便根据肽的序列推断其溶解度、溶血、与SHP-2的结合力和无污活性。我们对我们的 PU 学习方法的预测性能进行了评估,结果表明,与经典的正负(PN)分类方法相比,我们的 PU 学习方法仅使用正向数据,就能获得具有竞争力的性能,因为在正向和负向实例中都能获得正向数据。


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
