Alberto J. Taurozzi, Patrick L. Rüther, Ioannis Patramanis, Claire Koenig, Ryan Sinclair Paterson, Palesa P. Madupe, Florian Simon Harking, Frido Welker, Meaghan Mackie, Jazmín Ramos-Madrigal, Jesper V. Olsen, Enrico Cappellini
{"title":"Deep-time phylogenetic inference by paleoproteomic analysis of dental enamel","authors":"Alberto J. Taurozzi, Patrick L. Rüther, Ioannis Patramanis, Claire Koenig, Ryan Sinclair Paterson, Palesa P. Madupe, Florian Simon Harking, Frido Welker, Meaghan Mackie, Jazmín Ramos-Madrigal, Jesper V. Olsen, Enrico Cappellini","doi":"10.1038/s41596-024-00975-3","DOIUrl":null,"url":null,"abstract":"In temperate and subtropical regions, ancient proteins are reported to survive up to about 2 million years, far beyond the known limits of ancient DNA preservation in the same areas. Accordingly, their amino acid sequences currently represent the only source of genetic information available to pursue phylogenetic inference involving species that went extinct too long ago to be amenable for ancient DNA analysis. Here we present a complete workflow, including sample preparation, mass spectrometric data acquisition and computational analysis, to recover and interpret million-year-old dental enamel protein sequences. During sample preparation, the proteolytic digestion step, usually an integral part of conventional bottom-up proteomics, is omitted to increase the recovery of the randomly degraded peptides spontaneously generated by extensive diagenetic hydrolysis of ancient proteins over geological time. Similarly, we describe other solutions we have adopted to (1) authenticate the endogenous origin of the protein traces we identify, (2) detect and validate amino acid variation in the ancient protein sequences and (3) attempt phylogenetic inference. Sample preparation and data acquisition can be completed in 3–4 working days, while subsequent data analysis usually takes 2–5 days. The workflow described requires basic expertise in ancient biomolecules analysis, mass spectrometry-based proteomics and molecular phylogeny. Finally, we describe the limits of this approach and its potential for the reconstruction of evolutionary relationships in paleontology and paleoanthropology. Ancient proteins carry genetic information from fossils that are too old or degraded for ancient DNA recovery. This protocol describes the extraction and tandem mass spectrometry sequencing of million-year-old dental enamel proteins for phylogenetic inference.","PeriodicalId":18901,"journal":{"name":"Nature Protocols","volume":"19 7","pages":"2085-2116"},"PeriodicalIF":16.0000,"publicationDate":"2024-04-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.nature.com/articles/s41596-024-00975-3.pdf","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Nature Protocols","FirstCategoryId":"99","ListUrlMain":"https://www.nature.com/articles/s41596-024-00975-3","RegionNum":1,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"BIOCHEMICAL RESEARCH METHODS","Score":null,"Total":0}
引用次数: 0
Abstract
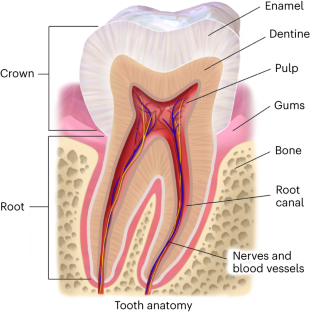
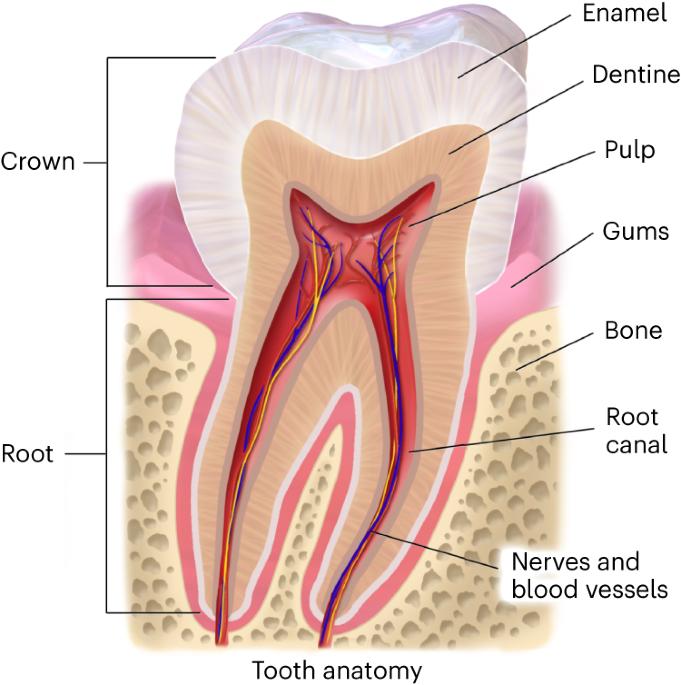
In temperate and subtropical regions, ancient proteins are reported to survive up to about 2 million years, far beyond the known limits of ancient DNA preservation in the same areas. Accordingly, their amino acid sequences currently represent the only source of genetic information available to pursue phylogenetic inference involving species that went extinct too long ago to be amenable for ancient DNA analysis. Here we present a complete workflow, including sample preparation, mass spectrometric data acquisition and computational analysis, to recover and interpret million-year-old dental enamel protein sequences. During sample preparation, the proteolytic digestion step, usually an integral part of conventional bottom-up proteomics, is omitted to increase the recovery of the randomly degraded peptides spontaneously generated by extensive diagenetic hydrolysis of ancient proteins over geological time. Similarly, we describe other solutions we have adopted to (1) authenticate the endogenous origin of the protein traces we identify, (2) detect and validate amino acid variation in the ancient protein sequences and (3) attempt phylogenetic inference. Sample preparation and data acquisition can be completed in 3–4 working days, while subsequent data analysis usually takes 2–5 days. The workflow described requires basic expertise in ancient biomolecules analysis, mass spectrometry-based proteomics and molecular phylogeny. Finally, we describe the limits of this approach and its potential for the reconstruction of evolutionary relationships in paleontology and paleoanthropology. Ancient proteins carry genetic information from fossils that are too old or degraded for ancient DNA recovery. This protocol describes the extraction and tandem mass spectrometry sequencing of million-year-old dental enamel proteins for phylogenetic inference.
期刊介绍:
Nature Protocols focuses on publishing protocols used to address significant biological and biomedical science research questions, including methods grounded in physics and chemistry with practical applications to biological problems. The journal caters to a primary audience of research scientists and, as such, exclusively publishes protocols with research applications. Protocols primarily aimed at influencing patient management and treatment decisions are not featured.
The specific techniques covered encompass a wide range, including but not limited to: Biochemistry, Cell biology, Cell culture, Chemical modification, Computational biology, Developmental biology, Epigenomics, Genetic analysis, Genetic modification, Genomics, Imaging, Immunology, Isolation, purification, and separation, Lipidomics, Metabolomics, Microbiology, Model organisms, Nanotechnology, Neuroscience, Nucleic-acid-based molecular biology, Pharmacology, Plant biology, Protein analysis, Proteomics, Spectroscopy, Structural biology, Synthetic chemistry, Tissue culture, Toxicology, and Virology.


 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
