{"title":"Joint training with local soft attention and dual cross-neighbor label smoothing for unsupervised person re-identification","authors":"Qing Han, Longfei Li, Weidong Min, Qi Wang, Qingpeng Zeng, Shimiao Cui, Jiongjin Chen","doi":"10.1007/s41095-023-0354-4","DOIUrl":null,"url":null,"abstract":"<p>Existing unsupervised person re-identification approaches fail to fully capture the fine-grained features of local regions, which can result in people with similar appearances and different identities being assigned the same label after clustering. The identity-independent information contained in different local regions leads to different levels of local noise. To address these challenges, joint training with local soft attention and dual cross-neighbor label smoothing (DCLS) is proposed in this study. First, the joint training is divided into global and local parts, whereby a soft attention mechanism is proposed for the local branch to accurately capture the subtle differences in local regions, which improves the ability of the re-identification model in identifying a person’s local significant features. Second, DCLS is designed to progressively mitigate label noise in different local regions. The DCLS uses global and local similarity metrics to semantically align the global and local regions of the person and further determines the proximity association between local regions through the cross information of neighboring regions, thereby achieving label smoothing of the global and local regions throughout the training process. In extensive experiments, the proposed method outperformed existing methods under unsupervised settings on several standard person re-identification datasets.\n</p>","PeriodicalId":37301,"journal":{"name":"Computational Visual Media","volume":"36 1","pages":""},"PeriodicalIF":18.3000,"publicationDate":"2024-04-27","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computational Visual Media","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s41095-023-0354-4","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
引用次数: 0
Abstract
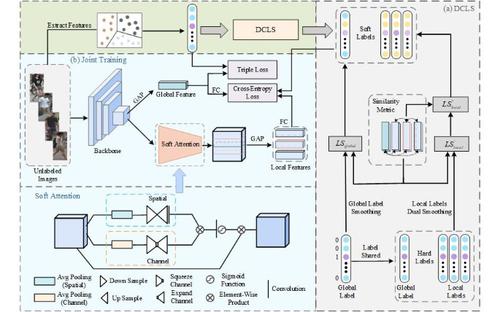
Existing unsupervised person re-identification approaches fail to fully capture the fine-grained features of local regions, which can result in people with similar appearances and different identities being assigned the same label after clustering. The identity-independent information contained in different local regions leads to different levels of local noise. To address these challenges, joint training with local soft attention and dual cross-neighbor label smoothing (DCLS) is proposed in this study. First, the joint training is divided into global and local parts, whereby a soft attention mechanism is proposed for the local branch to accurately capture the subtle differences in local regions, which improves the ability of the re-identification model in identifying a person’s local significant features. Second, DCLS is designed to progressively mitigate label noise in different local regions. The DCLS uses global and local similarity metrics to semantically align the global and local regions of the person and further determines the proximity association between local regions through the cross information of neighboring regions, thereby achieving label smoothing of the global and local regions throughout the training process. In extensive experiments, the proposed method outperformed existing methods under unsupervised settings on several standard person re-identification datasets.
期刊介绍:
Computational Visual Media is a peer-reviewed open access journal. It publishes original high-quality research papers and significant review articles on novel ideas, methods, and systems relevant to visual media.
Computational Visual Media publishes articles that focus on, but are not limited to, the following areas:
• Editing and composition of visual media
• Geometric computing for images and video
• Geometry modeling and processing
• Machine learning for visual media
• Physically based animation
• Realistic rendering
• Recognition and understanding of visual media
• Visual computing for robotics
• Visualization and visual analytics
Other interdisciplinary research into visual media that combines aspects of computer graphics, computer vision, image and video processing, geometric computing, and machine learning is also within the journal''s scope.
This is an open access journal, published quarterly by Tsinghua University Press and Springer. The open access fees (article-processing charges) are fully sponsored by Tsinghua University, China. Authors can publish in the journal without any additional charges.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
