{"title":"A stacked convolutional neural network framework with multi-scale attention mechanism for text-independent voiceprint recognition","authors":"V. Karthikeyan, S. Suja Priyadharsini","doi":"10.1007/s10044-024-01278-9","DOIUrl":null,"url":null,"abstract":"<p>Short-utterance speaker identification is a difficult area of study in natural language processing (NLP). Most cutting-edge experimental approaches for speech processing make use of convolutional neural networks (CNNs) and deep neural networks and analyse data in a unidirectional stream of time. In the past, approaches for identifying speakers that utilised CNNs often made use of highly dense or vast layers, leading to a large number of factors and significant computational expenses. In this article, we provide a novel multi-scale attention-focused 1-dimensional convolutional neural network (MSA-CNN) for recognising speakers that combines L1 and L2 norms. The multi-scale convolutional training architecture was developed to autonomously extract multi-scale characteristics of raw audio data by employing a variety of filter banks. In order for the multi-scale system to emphasis on important speaker feature characteristics in varying settings, a novel attention mechanism was built. In the end, it was combined and applied to the suggested multi-layered convolutional neural network framework to identify the speakers' labels. The recommended network model was tested on a number of standard voice databases and real time recorded corpus. The findings from the experiments demonstrate that our methodology outperformed a baseline CNN scheme (without an attention mechanism) in addition to conventional speaker identification techniques involving feature engineering, achieving an accuracy rate of 97.94% across numerous databases as well as distortion constraints.</p>","PeriodicalId":54639,"journal":{"name":"Pattern Analysis and Applications","volume":"21 1","pages":""},"PeriodicalIF":2.0000,"publicationDate":"2024-04-27","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Pattern Analysis and Applications","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10044-024-01278-9","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
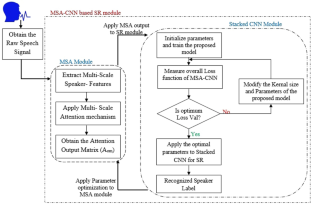
Short-utterance speaker identification is a difficult area of study in natural language processing (NLP). Most cutting-edge experimental approaches for speech processing make use of convolutional neural networks (CNNs) and deep neural networks and analyse data in a unidirectional stream of time. In the past, approaches for identifying speakers that utilised CNNs often made use of highly dense or vast layers, leading to a large number of factors and significant computational expenses. In this article, we provide a novel multi-scale attention-focused 1-dimensional convolutional neural network (MSA-CNN) for recognising speakers that combines L1 and L2 norms. The multi-scale convolutional training architecture was developed to autonomously extract multi-scale characteristics of raw audio data by employing a variety of filter banks. In order for the multi-scale system to emphasis on important speaker feature characteristics in varying settings, a novel attention mechanism was built. In the end, it was combined and applied to the suggested multi-layered convolutional neural network framework to identify the speakers' labels. The recommended network model was tested on a number of standard voice databases and real time recorded corpus. The findings from the experiments demonstrate that our methodology outperformed a baseline CNN scheme (without an attention mechanism) in addition to conventional speaker identification techniques involving feature engineering, achieving an accuracy rate of 97.94% across numerous databases as well as distortion constraints.
期刊介绍:
The journal publishes high quality articles in areas of fundamental research in intelligent pattern analysis and applications in computer science and engineering. It aims to provide a forum for original research which describes novel pattern analysis techniques and industrial applications of the current technology. In addition, the journal will also publish articles on pattern analysis applications in medical imaging. The journal solicits articles that detail new technology and methods for pattern recognition and analysis in applied domains including, but not limited to, computer vision and image processing, speech analysis, robotics, multimedia, document analysis, character recognition, knowledge engineering for pattern recognition, fractal analysis, and intelligent control. The journal publishes articles on the use of advanced pattern recognition and analysis methods including statistical techniques, neural networks, genetic algorithms, fuzzy pattern recognition, machine learning, and hardware implementations which are either relevant to the development of pattern analysis as a research area or detail novel pattern analysis applications. Papers proposing new classifier systems or their development, pattern analysis systems for real-time applications, fuzzy and temporal pattern recognition and uncertainty management in applied pattern recognition are particularly solicited.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
