{"title":"High-performance computing in healthcare:an automatic literature analysis perspective","authors":"Jieyi Li, Shuai Wang, Stevan Rudinac, Anwar Osseyran","doi":"10.1186/s40537-024-00929-2","DOIUrl":null,"url":null,"abstract":"<p>The adoption of high-performance computing (HPC) in healthcare has gained significant attention in recent years, driving advancements in medical research and clinical practice. Exploring the literature on HPC implementation in healthcare is valuable for decision-makers as it provides insights into potential areas for further investigation and investment. However, manually analyzing the vast number of scholarly articles is a challenging and time-consuming task. Fortunately, topic modeling techniques offer the capacity to process extensive volumes of scientific literature, identifying key trends within the field. This paper presents an automatic literature analysis framework based on a state-of-art vector-based topic modeling algorithm with multiple embedding techniques, unveiling the research trends surrounding HPC utilization in healthcare. The proposed pipeline consists of four phases: paper extraction, data preprocessing, topic modeling and outlier detection, followed by visualization. It enables the automatic extraction of meaningful topics, exploration of their interrelationships, and identification of emerging research directions in an intuitive manner. The findings highlight the transition of HPC adoption in healthcare from traditional numerical simulation and surgical visualization to emerging topics such as drug discovery, AI-driven medical image analysis, and genomic analysis, as well as correlations and interdisciplinary connections among application domains.</p>","PeriodicalId":15158,"journal":{"name":"Journal of Big Data","volume":"91 1","pages":""},"PeriodicalIF":6.4000,"publicationDate":"2024-05-02","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Big Data","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1186/s40537-024-00929-2","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, THEORY & METHODS","Score":null,"Total":0}
引用次数: 0
Abstract
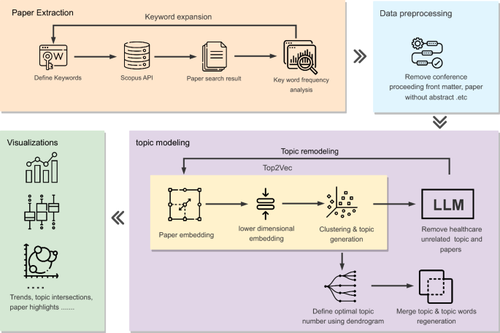
The adoption of high-performance computing (HPC) in healthcare has gained significant attention in recent years, driving advancements in medical research and clinical practice. Exploring the literature on HPC implementation in healthcare is valuable for decision-makers as it provides insights into potential areas for further investigation and investment. However, manually analyzing the vast number of scholarly articles is a challenging and time-consuming task. Fortunately, topic modeling techniques offer the capacity to process extensive volumes of scientific literature, identifying key trends within the field. This paper presents an automatic literature analysis framework based on a state-of-art vector-based topic modeling algorithm with multiple embedding techniques, unveiling the research trends surrounding HPC utilization in healthcare. The proposed pipeline consists of four phases: paper extraction, data preprocessing, topic modeling and outlier detection, followed by visualization. It enables the automatic extraction of meaningful topics, exploration of their interrelationships, and identification of emerging research directions in an intuitive manner. The findings highlight the transition of HPC adoption in healthcare from traditional numerical simulation and surgical visualization to emerging topics such as drug discovery, AI-driven medical image analysis, and genomic analysis, as well as correlations and interdisciplinary connections among application domains.
期刊介绍:
The Journal of Big Data publishes high-quality, scholarly research papers, methodologies, and case studies covering a broad spectrum of topics, from big data analytics to data-intensive computing and all applications of big data research. It addresses challenges facing big data today and in the future, including data capture and storage, search, sharing, analytics, technologies, visualization, architectures, data mining, machine learning, cloud computing, distributed systems, and scalable storage. The journal serves as a seminal source of innovative material for academic researchers and practitioners alike.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
