Arezoo Sadeghzadeh , A.F.M. Shahen Shah , Md Baharul Islam
{"title":"MLMSign: Multi-lingual multi-modal illumination-invariant sign language recognition","authors":"Arezoo Sadeghzadeh , A.F.M. Shahen Shah , Md Baharul Islam","doi":"10.1016/j.iswa.2024.200384","DOIUrl":null,"url":null,"abstract":"<div><p>Sign language (SL) serves as a visual communication tool bearing great significance for deaf people to interact with others and facilitate their daily life. Wide varieties of SLs and the lack of interpretation knowledge necessitate developing automated sign language recognition (SLR) systems to attenuate the communication gap between the deaf and hearing communities. Despite numerous advanced static SLR systems, they are not practical and favorable enough for real-life scenarios once assessed simultaneously from different critical aspects: accuracy in dealing with high intra- and slight inter-class variations, robustness, computational complexity, and generalization ability. To this end, we propose a novel multi-lingual multi-modal SLR system, namely <em>MLMSign</em>, by taking full strengths of hand-crafted features and deep learning models to enhance the performance and the robustness of the system against illumination changes while minimizing computational cost. The RGB sign images and 2D visualizations of their hand-crafted features, i.e., Histogram of Oriented Gradients (HOG) features and <span><math><msup><mrow><mi>a</mi></mrow><mrow><mo>∗</mo></mrow></msup></math></span> channel of <span><math><mrow><msup><mrow><mi>L</mi></mrow><mrow><mo>∗</mo></mrow></msup><msup><mrow><mi>a</mi></mrow><mrow><mo>∗</mo></mrow></msup><msup><mrow><mi>b</mi></mrow><mrow><mo>∗</mo></mrow></msup></mrow></math></span> color space, are employed as three input modalities to train a novel Convolutional Neural Network (CNN). The number of layers, filters, kernel size, learning rate, and optimization technique are carefully selected through an extensive parametric study to minimize the computational cost without compromising accuracy. The system’s performance and robustness are significantly enhanced by jointly deploying the models of these three modalities through ensemble learning. The impact of each modality is optimized based on their impact coefficient determined by grid search. In addition to the comprehensive quantitative assessment, the capabilities of our proposed model and the effectiveness of ensembling over three modalities are evaluated qualitatively using the Grad-CAM visualization model. Experimental results on the test data with additional illumination changes verify the high robustness of our system in dealing with overexposed and underexposed lighting conditions. Achieving a high accuracy (<span><math><mrow><mo>></mo><mn>99</mn><mo>.</mo><mn>33</mn><mtext>%</mtext></mrow></math></span>) on six benchmark datasets (i.e., Massey, Static ASL, NUS II, TSL Fingerspelling, BdSL36v1, and PSL) demonstrates that our system notably outperforms the recent state-of-the-art approaches with a minimum number of parameters and high generalization ability over complex datasets. Its promising performance for four different sign languages makes it a feasible system for multi-lingual applications.</p></div>","PeriodicalId":100684,"journal":{"name":"Intelligent Systems with Applications","volume":"22 ","pages":"Article 200384"},"PeriodicalIF":4.3000,"publicationDate":"2024-05-06","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.sciencedirect.com/science/article/pii/S2667305324000590/pdfft?md5=9a754731551f7380f553abb3c302ac3a&pid=1-s2.0-S2667305324000590-main.pdf","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Intelligent Systems with Applications","FirstCategoryId":"1085","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2667305324000590","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
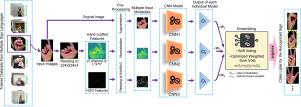
Sign language (SL) serves as a visual communication tool bearing great significance for deaf people to interact with others and facilitate their daily life. Wide varieties of SLs and the lack of interpretation knowledge necessitate developing automated sign language recognition (SLR) systems to attenuate the communication gap between the deaf and hearing communities. Despite numerous advanced static SLR systems, they are not practical and favorable enough for real-life scenarios once assessed simultaneously from different critical aspects: accuracy in dealing with high intra- and slight inter-class variations, robustness, computational complexity, and generalization ability. To this end, we propose a novel multi-lingual multi-modal SLR system, namely MLMSign, by taking full strengths of hand-crafted features and deep learning models to enhance the performance and the robustness of the system against illumination changes while minimizing computational cost. The RGB sign images and 2D visualizations of their hand-crafted features, i.e., Histogram of Oriented Gradients (HOG) features and channel of color space, are employed as three input modalities to train a novel Convolutional Neural Network (CNN). The number of layers, filters, kernel size, learning rate, and optimization technique are carefully selected through an extensive parametric study to minimize the computational cost without compromising accuracy. The system’s performance and robustness are significantly enhanced by jointly deploying the models of these three modalities through ensemble learning. The impact of each modality is optimized based on their impact coefficient determined by grid search. In addition to the comprehensive quantitative assessment, the capabilities of our proposed model and the effectiveness of ensembling over three modalities are evaluated qualitatively using the Grad-CAM visualization model. Experimental results on the test data with additional illumination changes verify the high robustness of our system in dealing with overexposed and underexposed lighting conditions. Achieving a high accuracy () on six benchmark datasets (i.e., Massey, Static ASL, NUS II, TSL Fingerspelling, BdSL36v1, and PSL) demonstrates that our system notably outperforms the recent state-of-the-art approaches with a minimum number of parameters and high generalization ability over complex datasets. Its promising performance for four different sign languages makes it a feasible system for multi-lingual applications.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
