{"title":"Trusted 3D self-supervised representation learning with cross-modal settings","authors":"Xu Han, Haozhe Cheng, Pengcheng Shi, Jihua Zhu","doi":"10.1007/s00138-024-01556-w","DOIUrl":null,"url":null,"abstract":"<p>Cross-modal setting employing 2D images and 3D point clouds in self-supervised representation learning is proven to be an effective way to enhance visual perception capabilities. However, different modalities have different data formats and representations. Directly using features extracted from cross-modal datasets may lead to information conflicting and collapsing. We refer to this problem as uncertainty in network learning. Therefore, reducing uncertainty to obtain trusted descriptions has become the key to improving network performance. Motivated by this, we propose our trusted cross-modal network in self-supervised learning (TCMSS). It can obtain trusted descriptions by a trusted combination module as well as improve network performance with a well-designed loss function. In the trusted combination module, we utilize the Dirichlet distribution and the subjective logic to parameterize the features and acquire probabilistic uncertainty at the same. Then, the Dempster-Shafer Theory (DST) is used to obtain trusted descriptions by weighting uncertainty to the parameterized results. We have also designed our trusted domain loss function, including domain loss and trusted loss. It can effectively improve the prediction accuracy of the network by applying contrastive learning between different feature descriptions. The experimental results show that our model outperforms previous results on linear classification in ScanObjectNN as well as few-shot classification in both ModelNet40 and ScanObjectNN. In addition, part segmentation also reports a superior result to previous methods in ShapeNet. Further, the ablation studies validate the potency of our method for a better point cloud understanding.</p>","PeriodicalId":51116,"journal":{"name":"Machine Vision and Applications","volume":"32 1","pages":""},"PeriodicalIF":2.3000,"publicationDate":"2024-06-02","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Machine Vision and Applications","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s00138-024-01556-w","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
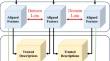
Cross-modal setting employing 2D images and 3D point clouds in self-supervised representation learning is proven to be an effective way to enhance visual perception capabilities. However, different modalities have different data formats and representations. Directly using features extracted from cross-modal datasets may lead to information conflicting and collapsing. We refer to this problem as uncertainty in network learning. Therefore, reducing uncertainty to obtain trusted descriptions has become the key to improving network performance. Motivated by this, we propose our trusted cross-modal network in self-supervised learning (TCMSS). It can obtain trusted descriptions by a trusted combination module as well as improve network performance with a well-designed loss function. In the trusted combination module, we utilize the Dirichlet distribution and the subjective logic to parameterize the features and acquire probabilistic uncertainty at the same. Then, the Dempster-Shafer Theory (DST) is used to obtain trusted descriptions by weighting uncertainty to the parameterized results. We have also designed our trusted domain loss function, including domain loss and trusted loss. It can effectively improve the prediction accuracy of the network by applying contrastive learning between different feature descriptions. The experimental results show that our model outperforms previous results on linear classification in ScanObjectNN as well as few-shot classification in both ModelNet40 and ScanObjectNN. In addition, part segmentation also reports a superior result to previous methods in ShapeNet. Further, the ablation studies validate the potency of our method for a better point cloud understanding.
期刊介绍:
Machine Vision and Applications publishes high-quality technical contributions in machine vision research and development. Specifically, the editors encourage submittals in all applications and engineering aspects of image-related computing. In particular, original contributions dealing with scientific, commercial, industrial, military, and biomedical applications of machine vision, are all within the scope of the journal.
Particular emphasis is placed on engineering and technology aspects of image processing and computer vision.
The following aspects of machine vision applications are of interest: algorithms, architectures, VLSI implementations, AI techniques and expert systems for machine vision, front-end sensing, multidimensional and multisensor machine vision, real-time techniques, image databases, virtual reality and visualization. Papers must include a significant experimental validation component.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
