Diego García-Gil, Salvador García, Ning Xiong, Francisco Herrera
{"title":"Smart Data Driven Decision Trees Ensemble Methodology for Imbalanced Big Data","authors":"Diego García-Gil, Salvador García, Ning Xiong, Francisco Herrera","doi":"10.1007/s12559-024-10295-z","DOIUrl":null,"url":null,"abstract":"<p>Differences in data size per class, also known as imbalanced data distribution, have become a common problem affecting data quality. Big Data scenarios pose a new challenge to traditional imbalanced classification algorithms, since they are not prepared to work with such amount of data. Split data strategies and lack of data in the minority class due to the use of MapReduce paradigm have posed new challenges for tackling the imbalance between classes in Big Data scenarios. Ensembles have been shown to be able to successfully address imbalanced data problems. Smart Data refers to data of enough quality to achieve high-performance models. The combination of ensembles and Smart Data, achieved through Big Data preprocessing, should be a great synergy. In this paper, we propose a novel Smart Data driven Decision Trees Ensemble methodology for addressing the imbalanced classification problem in Big Data domains, namely SD_DeTE methodology. This methodology is based on the learning of different decision trees using distributed quality data for the ensemble process. This quality data is achieved by fusing random discretization, principal components analysis, and clustering-based random oversampling for obtaining different Smart Data versions of the original data. Experiments carried out in 21 binary adapted datasets have shown that our methodology outperforms random forest.</p>","PeriodicalId":51243,"journal":{"name":"Cognitive Computation","volume":"266 1","pages":""},"PeriodicalIF":4.3000,"publicationDate":"2024-05-31","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Cognitive Computation","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s12559-024-10295-z","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
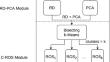
Differences in data size per class, also known as imbalanced data distribution, have become a common problem affecting data quality. Big Data scenarios pose a new challenge to traditional imbalanced classification algorithms, since they are not prepared to work with such amount of data. Split data strategies and lack of data in the minority class due to the use of MapReduce paradigm have posed new challenges for tackling the imbalance between classes in Big Data scenarios. Ensembles have been shown to be able to successfully address imbalanced data problems. Smart Data refers to data of enough quality to achieve high-performance models. The combination of ensembles and Smart Data, achieved through Big Data preprocessing, should be a great synergy. In this paper, we propose a novel Smart Data driven Decision Trees Ensemble methodology for addressing the imbalanced classification problem in Big Data domains, namely SD_DeTE methodology. This methodology is based on the learning of different decision trees using distributed quality data for the ensemble process. This quality data is achieved by fusing random discretization, principal components analysis, and clustering-based random oversampling for obtaining different Smart Data versions of the original data. Experiments carried out in 21 binary adapted datasets have shown that our methodology outperforms random forest.
期刊介绍:
Cognitive Computation is an international, peer-reviewed, interdisciplinary journal that publishes cutting-edge articles describing original basic and applied work involving biologically-inspired computational accounts of all aspects of natural and artificial cognitive systems. It provides a new platform for the dissemination of research, current practices and future trends in the emerging discipline of cognitive computation that bridges the gap between life sciences, social sciences, engineering, physical and mathematical sciences, and humanities.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
