Sita Sirisha Madugula, Pranav Pujar, Bharani Nammi, Shouyi Wang, Vindi M. Jayasinghe-Arachchige, Tyler Pham, Dominic Mashburn, Maria Artiles and Jin Liu*,
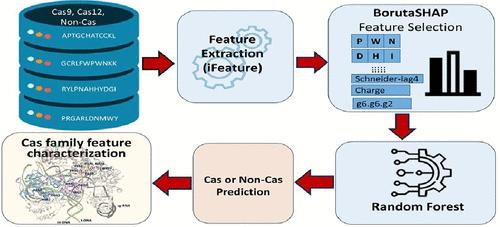
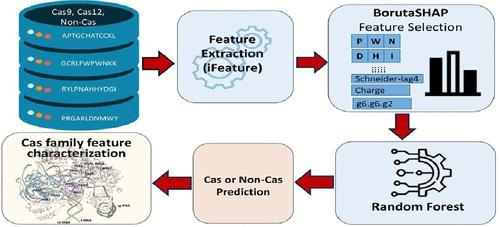
{"title":"Identification of Family-Specific Features in Cas9 and Cas12 Proteins: A Machine Learning Approach Using Complete Protein Feature Spectrum","authors":"Sita Sirisha Madugula, Pranav Pujar, Bharani Nammi, Shouyi Wang, Vindi M. Jayasinghe-Arachchige, Tyler Pham, Dominic Mashburn, Maria Artiles and Jin Liu*, ","doi":"10.1021/acs.jcim.4c00625","DOIUrl":null,"url":null,"abstract":"<p >The recent development of CRISPR-Cas technology holds promise to correct gene-level defects for genetic diseases. The key element of the CRISPR-Cas system is the Cas protein, a nuclease that can edit the gene of interest assisted by guide RNA. However, these Cas proteins suffer from inherent limitations such as large size, low cleavage efficiency, and off-target effects, hindering their widespread application as a gene editing tool. Therefore, there is a need to identify novel Cas proteins with improved editing properties, for which it is necessary to understand the underlying features governing the Cas families. In this study, we aim to elucidate the unique protein features associated with Cas9 and Cas12 families and identify the features distinguishing each family from non-Cas proteins. Here, we built Random Forest (RF) binary classifiers to distinguish Cas12 and Cas9 proteins from non-Cas proteins, respectively, using the complete protein feature spectrum (13,494 features) encoding various physiochemical, topological, constitutional, and coevolutionary information on Cas proteins. Furthermore, we built multiclass RF classifiers differentiating Cas9, Cas12, and non-Cas proteins. All the models were evaluated rigorously on the test and independent data sets. The Cas12 and Cas9 binary models achieved a high overall accuracy of 92% and 95% on their respective independent data sets, while the multiclass classifier achieved an F1 score of close to 0.98. We observed that Quasi-Sequence-Order (QSO) descriptors like Schneider.lag and Composition descriptors like charge, volume, and polarizability are predominant in the Cas12 family. Conversely Amino Acid Composition descriptors, especially Tripeptide Composition (TPC), predominate the Cas9 family. Four of the top 10 descriptors identified in Cas9 classification are tripeptides PWN, PYY, HHA, and DHI, which are seen to be conserved across all Cas9 proteins and located within different catalytically important domains of the <i>Streptococcus pyogenes</i> Cas9 (SpCas9) structure. Among these, DHI and HHA are well-known to be involved in the DNA cleavage activity of the SpCas9 protein. Mutation studies have highlighted the significance of the PWN tripeptide in PAM recognition and DNA cleavage activity of SpCas9, while Y450 from the PYY tripeptide plays a crucial role in reducing off-target effects and improving the specificity in SpCas9. Leveraging our machine learning (ML) pipeline, we identified numerous Cas9 and Cas12 family-specific features. These features offer valuable insights for future experimental and computational studies aiming at designing Cas systems with enhanced gene-editing properties. These features suggest plausible structural modifications that can effectively guide the development of Cas proteins with improved editing capabilities.</p>","PeriodicalId":44,"journal":{"name":"Journal of Chemical Information and Modeling ","volume":"64 12","pages":"4897–4911"},"PeriodicalIF":5.3000,"publicationDate":"2024-06-05","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Chemical Information and Modeling ","FirstCategoryId":"92","ListUrlMain":"https://pubs.acs.org/doi/10.1021/acs.jcim.4c00625","RegionNum":2,"RegionCategory":"化学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"CHEMISTRY, MEDICINAL","Score":null,"Total":0}
引用次数: 0
Abstract
The recent development of CRISPR-Cas technology holds promise to correct gene-level defects for genetic diseases. The key element of the CRISPR-Cas system is the Cas protein, a nuclease that can edit the gene of interest assisted by guide RNA. However, these Cas proteins suffer from inherent limitations such as large size, low cleavage efficiency, and off-target effects, hindering their widespread application as a gene editing tool. Therefore, there is a need to identify novel Cas proteins with improved editing properties, for which it is necessary to understand the underlying features governing the Cas families. In this study, we aim to elucidate the unique protein features associated with Cas9 and Cas12 families and identify the features distinguishing each family from non-Cas proteins. Here, we built Random Forest (RF) binary classifiers to distinguish Cas12 and Cas9 proteins from non-Cas proteins, respectively, using the complete protein feature spectrum (13,494 features) encoding various physiochemical, topological, constitutional, and coevolutionary information on Cas proteins. Furthermore, we built multiclass RF classifiers differentiating Cas9, Cas12, and non-Cas proteins. All the models were evaluated rigorously on the test and independent data sets. The Cas12 and Cas9 binary models achieved a high overall accuracy of 92% and 95% on their respective independent data sets, while the multiclass classifier achieved an F1 score of close to 0.98. We observed that Quasi-Sequence-Order (QSO) descriptors like Schneider.lag and Composition descriptors like charge, volume, and polarizability are predominant in the Cas12 family. Conversely Amino Acid Composition descriptors, especially Tripeptide Composition (TPC), predominate the Cas9 family. Four of the top 10 descriptors identified in Cas9 classification are tripeptides PWN, PYY, HHA, and DHI, which are seen to be conserved across all Cas9 proteins and located within different catalytically important domains of the Streptococcus pyogenes Cas9 (SpCas9) structure. Among these, DHI and HHA are well-known to be involved in the DNA cleavage activity of the SpCas9 protein. Mutation studies have highlighted the significance of the PWN tripeptide in PAM recognition and DNA cleavage activity of SpCas9, while Y450 from the PYY tripeptide plays a crucial role in reducing off-target effects and improving the specificity in SpCas9. Leveraging our machine learning (ML) pipeline, we identified numerous Cas9 and Cas12 family-specific features. These features offer valuable insights for future experimental and computational studies aiming at designing Cas systems with enhanced gene-editing properties. These features suggest plausible structural modifications that can effectively guide the development of Cas proteins with improved editing capabilities.
期刊介绍:
The Journal of Chemical Information and Modeling publishes papers reporting new methodology and/or important applications in the fields of chemical informatics and molecular modeling. Specific topics include the representation and computer-based searching of chemical databases, molecular modeling, computer-aided molecular design of new materials, catalysts, or ligands, development of new computational methods or efficient algorithms for chemical software, and biopharmaceutical chemistry including analyses of biological activity and other issues related to drug discovery.
Astute chemists, computer scientists, and information specialists look to this monthly’s insightful research studies, programming innovations, and software reviews to keep current with advances in this integral, multidisciplinary field.
As a subscriber you’ll stay abreast of database search systems, use of graph theory in chemical problems, substructure search systems, pattern recognition and clustering, analysis of chemical and physical data, molecular modeling, graphics and natural language interfaces, bibliometric and citation analysis, and synthesis design and reactions databases.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
