{"title":"ACDMBI: A deep learning model based on community division and multi-source biological information fusion predicts essential proteins","authors":"Pengli Lu, Jialong Tian","doi":"10.1016/j.compbiolchem.2024.108115","DOIUrl":null,"url":null,"abstract":"<div><p>Accurately identifying essential proteins is vital for drug research and disease diagnosis. Traditional centrality methods and machine learning approaches often face challenges in accurately discerning essential proteins, primarily relying on information derived from protein-protein interaction (PPI) networks. Despite attempts by some researchers to integrate biological data and PPI networks for predicting essential proteins, designing effective integration methods remains a challenge. In response to these challenges, this paper presents the ACDMBI model, specifically designed to overcome the aforementioned issues. ACDMBI is comprised of two key modules: feature extraction and classification. In terms of capturing relevant information, we draw insights from three distinct data sources. Initially, structural features of proteins are extracted from the PPI network through community division. Subsequently, these features are further optimized using Graph Convolutional Networks (GCN) and Graph Attention Networks (GAT). Moving forward, protein features are extracted from gene expression data utilizing Bidirectional Long Short-Term Memory networks (BiLSTM) and a multi-head self-attention mechanism. Finally, protein features are derived by mapping subcellular localization data to a one-dimensional vector and processing it through fully connected layers. In the classification phase, we integrate features extracted from three different data sources, crafting a multi-layer deep neural network (DNN) for protein classification prediction. Experimental results on brewing yeast data showcase the ACDMBI model’s superior performance, with AUC reaching 0.9533 and AUPR reaching 0.9153. Ablation experiments further reveal that the effective integration of features from diverse biological information significantly boosts the model’s performance.</p></div>","PeriodicalId":10616,"journal":{"name":"Computational Biology and Chemistry","volume":"112 ","pages":"Article 108115"},"PeriodicalIF":3.1000,"publicationDate":"2024-06-06","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computational Biology and Chemistry","FirstCategoryId":"99","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1476927124001038","RegionNum":4,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
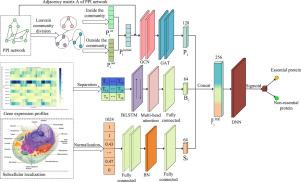
Accurately identifying essential proteins is vital for drug research and disease diagnosis. Traditional centrality methods and machine learning approaches often face challenges in accurately discerning essential proteins, primarily relying on information derived from protein-protein interaction (PPI) networks. Despite attempts by some researchers to integrate biological data and PPI networks for predicting essential proteins, designing effective integration methods remains a challenge. In response to these challenges, this paper presents the ACDMBI model, specifically designed to overcome the aforementioned issues. ACDMBI is comprised of two key modules: feature extraction and classification. In terms of capturing relevant information, we draw insights from three distinct data sources. Initially, structural features of proteins are extracted from the PPI network through community division. Subsequently, these features are further optimized using Graph Convolutional Networks (GCN) and Graph Attention Networks (GAT). Moving forward, protein features are extracted from gene expression data utilizing Bidirectional Long Short-Term Memory networks (BiLSTM) and a multi-head self-attention mechanism. Finally, protein features are derived by mapping subcellular localization data to a one-dimensional vector and processing it through fully connected layers. In the classification phase, we integrate features extracted from three different data sources, crafting a multi-layer deep neural network (DNN) for protein classification prediction. Experimental results on brewing yeast data showcase the ACDMBI model’s superior performance, with AUC reaching 0.9533 and AUPR reaching 0.9153. Ablation experiments further reveal that the effective integration of features from diverse biological information significantly boosts the model’s performance.
期刊介绍:
Computational Biology and Chemistry publishes original research papers and review articles in all areas of computational life sciences. High quality research contributions with a major computational component in the areas of nucleic acid and protein sequence research, molecular evolution, molecular genetics (functional genomics and proteomics), theory and practice of either biology-specific or chemical-biology-specific modeling, and structural biology of nucleic acids and proteins are particularly welcome. Exceptionally high quality research work in bioinformatics, systems biology, ecology, computational pharmacology, metabolism, biomedical engineering, epidemiology, and statistical genetics will also be considered.
Given their inherent uncertainty, protein modeling and molecular docking studies should be thoroughly validated. In the absence of experimental results for validation, the use of molecular dynamics simulations along with detailed free energy calculations, for example, should be used as complementary techniques to support the major conclusions. Submissions of premature modeling exercises without additional biological insights will not be considered.
Review articles will generally be commissioned by the editors and should not be submitted to the journal without explicit invitation. However prospective authors are welcome to send a brief (one to three pages) synopsis, which will be evaluated by the editors.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
