Zhongbin Fang , Xia Li , Xiangtai Li , Shen Zhao , Mengyuan Liu
{"title":"ModelNet-O: A large-scale synthetic dataset for occlusion-aware point cloud classification","authors":"Zhongbin Fang , Xia Li , Xiangtai Li , Shen Zhao , Mengyuan Liu","doi":"10.1016/j.cviu.2024.104060","DOIUrl":null,"url":null,"abstract":"<div><p>Recently, 3D point cloud classification has made significant progress with the help of many datasets. However, these datasets do not reflect the incomplete nature of real-world point clouds caused by <strong><em>occlusion</em></strong>, which limits the practical application of current methods. To bridge this gap, we propose ModelNet-O, <strong>a large-scale synthetic dataset of 123,041 samples</strong> that emulates real-world point clouds with self-occlusion caused by scanning from monocular cameras. ModelNet-O is <strong><em>10 times</em></strong> larger than existing datasets and offers more challenging cases to evaluate the robustness of existing methods. Our observation on ModelNet-O reveals that <strong>well-designed sparse structures can preserve structural information of point clouds under occlusion</strong>, motivating us to propose a robust point cloud processing method that leverages a critical point sampling (CPS) strategy in a multi-level manner. We term our method PointMLS. Through extensive experiments, we demonstrate that our PointMLS achieves state-of-the-art results on ModelNet-O and competitive results on regular datasets such as ModelNet40 and ScanObjectNN, and we also demonstrate its robustness and effectiveness. Code available: <span>https://github.com/fanglaosi/ModelNet-O_PointMLS</span><svg><path></path></svg>.</p></div>","PeriodicalId":50633,"journal":{"name":"Computer Vision and Image Understanding","volume":null,"pages":null},"PeriodicalIF":4.3000,"publicationDate":"2024-06-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computer Vision and Image Understanding","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1077314224001413","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
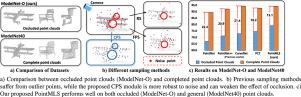
Recently, 3D point cloud classification has made significant progress with the help of many datasets. However, these datasets do not reflect the incomplete nature of real-world point clouds caused by occlusion, which limits the practical application of current methods. To bridge this gap, we propose ModelNet-O, a large-scale synthetic dataset of 123,041 samples that emulates real-world point clouds with self-occlusion caused by scanning from monocular cameras. ModelNet-O is 10 times larger than existing datasets and offers more challenging cases to evaluate the robustness of existing methods. Our observation on ModelNet-O reveals that well-designed sparse structures can preserve structural information of point clouds under occlusion, motivating us to propose a robust point cloud processing method that leverages a critical point sampling (CPS) strategy in a multi-level manner. We term our method PointMLS. Through extensive experiments, we demonstrate that our PointMLS achieves state-of-the-art results on ModelNet-O and competitive results on regular datasets such as ModelNet40 and ScanObjectNN, and we also demonstrate its robustness and effectiveness. Code available: https://github.com/fanglaosi/ModelNet-O_PointMLS.
期刊介绍:
The central focus of this journal is the computer analysis of pictorial information. Computer Vision and Image Understanding publishes papers covering all aspects of image analysis from the low-level, iconic processes of early vision to the high-level, symbolic processes of recognition and interpretation. A wide range of topics in the image understanding area is covered, including papers offering insights that differ from predominant views.
Research Areas Include:
• Theory
• Early vision
• Data structures and representations
• Shape
• Range
• Motion
• Matching and recognition
• Architecture and languages
• Vision systems



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
