Jarne Van den Herrewegen , Tom Tourwé , Maks Ovsjanikov , Francis wyffels
{"title":"Fine-tuning 3D foundation models for geometric object retrieval","authors":"Jarne Van den Herrewegen , Tom Tourwé , Maks Ovsjanikov , Francis wyffels","doi":"10.1016/j.cag.2024.103993","DOIUrl":null,"url":null,"abstract":"<div><p>Foundation models, such as ULIP-2 (Xue et al., 2023) recently projected forward the field of 3D deep learning. These models are trained with significantly more data and show superior representation learning capacity in many downstream tasks like 3D shape classification and few-shot part segmentation.</p><p>A particular characteristic of the recent 3D foundation models is that they are typically <em>multi-modal</em>, and involve image (2D) as well as caption (text) branches. This leads to an intricate interplay that benefits all modalities. At the same time, the nature of the <em>3D</em> encoders alone, involved in these foundation models is not well-understood. Specifically, there is little analysis on the utility of both pre-trained 3D features provided by these models, or their capacity to adapt to new downstream 3D data. Furthermore, existing studies typically focus on label-oriented downstream tasks, such as shape classification, and ignore other critical applications, such as 3D content-based object retrieval.</p><p>In this paper, we fill this gap and show, for the first time, how 3D foundation models can be leveraged for strong 3D-to-3D retrieval performance on seven different datasets, on par with state-of-the-art view-based architectures. We evaluate both the pre-trained foundation models, as well as their fine-tuned versions using downstream data. We compare supervised fine-tuning using classification labels against two self-supervised label-free fine-tuning methods. Importantly, we introduce and describe a methodology for fine-tuning, as we found this to be crucial to make transfer learning from 3D foundation models work in a stable manner.</p></div>","PeriodicalId":50628,"journal":{"name":"Computers & Graphics-Uk","volume":"122 ","pages":"Article 103993"},"PeriodicalIF":2.8000,"publicationDate":"2024-08-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.sciencedirect.com/science/article/pii/S0097849324001286/pdfft?md5=9cb01c40df89ca64e783dcd0f63e3f33&pid=1-s2.0-S0097849324001286-main.pdf","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computers & Graphics-Uk","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0097849324001286","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/7/3 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
引用次数: 0
Abstract
Foundation models, such as ULIP-2 (Xue et al., 2023) recently projected forward the field of 3D deep learning. These models are trained with significantly more data and show superior representation learning capacity in many downstream tasks like 3D shape classification and few-shot part segmentation.
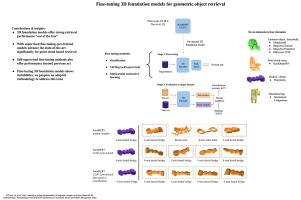
A particular characteristic of the recent 3D foundation models is that they are typically multi-modal, and involve image (2D) as well as caption (text) branches. This leads to an intricate interplay that benefits all modalities. At the same time, the nature of the 3D encoders alone, involved in these foundation models is not well-understood. Specifically, there is little analysis on the utility of both pre-trained 3D features provided by these models, or their capacity to adapt to new downstream 3D data. Furthermore, existing studies typically focus on label-oriented downstream tasks, such as shape classification, and ignore other critical applications, such as 3D content-based object retrieval.
In this paper, we fill this gap and show, for the first time, how 3D foundation models can be leveraged for strong 3D-to-3D retrieval performance on seven different datasets, on par with state-of-the-art view-based architectures. We evaluate both the pre-trained foundation models, as well as their fine-tuned versions using downstream data. We compare supervised fine-tuning using classification labels against two self-supervised label-free fine-tuning methods. Importantly, we introduce and describe a methodology for fine-tuning, as we found this to be crucial to make transfer learning from 3D foundation models work in a stable manner.
期刊介绍:
Computers & Graphics is dedicated to disseminate information on research and applications of computer graphics (CG) techniques. The journal encourages articles on:
1. Research and applications of interactive computer graphics. We are particularly interested in novel interaction techniques and applications of CG to problem domains.
2. State-of-the-art papers on late-breaking, cutting-edge research on CG.
3. Information on innovative uses of graphics principles and technologies.
4. Tutorial papers on both teaching CG principles and innovative uses of CG in education.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
