Mateja Napravnik, Franko Hržić, Sebastian Tschauner, Ivan Štajduhar
{"title":"Building RadiologyNET: an unsupervised approach to annotating a large-scale multimodal medical database.","authors":"Mateja Napravnik, Franko Hržić, Sebastian Tschauner, Ivan Štajduhar","doi":"10.1186/s13040-024-00373-1","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The use of machine learning in medical diagnosis and treatment has grown significantly in recent years with the development of computer-aided diagnosis systems, often based on annotated medical radiology images. However, the lack of large annotated image datasets remains a major obstacle, as the annotation process is time-consuming and costly. This study aims to overcome this challenge by proposing an automated method for annotating a large database of medical radiology images based on their semantic similarity.</p><p><strong>Results: </strong>An automated, unsupervised approach is used to create a large annotated dataset of medical radiology images originating from the Clinical Hospital Centre Rijeka, Croatia. The pipeline is built by data-mining three different types of medical data: images, DICOM metadata and narrative diagnoses. The optimal feature extractors are then integrated into a multimodal representation, which is then clustered to create an automated pipeline for labelling a precursor dataset of 1,337,926 medical images into 50 clusters of visually similar images. The quality of the clusters is assessed by examining their homogeneity and mutual information, taking into account the anatomical region and modality representation.</p><p><strong>Conclusions: </strong>The results indicate that fusing the embeddings of all three data sources together provides the best results for the task of unsupervised clustering of large-scale medical data and leads to the most concise clusters. Hence, this work marks the initial step towards building a much larger and more fine-grained annotated dataset of medical radiology images.</p>","PeriodicalId":48947,"journal":{"name":"Biodata Mining","volume":"17 1","pages":"22"},"PeriodicalIF":6.1000,"publicationDate":"2024-07-12","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11245804/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biodata Mining","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13040-024-00373-1","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
Background: The use of machine learning in medical diagnosis and treatment has grown significantly in recent years with the development of computer-aided diagnosis systems, often based on annotated medical radiology images. However, the lack of large annotated image datasets remains a major obstacle, as the annotation process is time-consuming and costly. This study aims to overcome this challenge by proposing an automated method for annotating a large database of medical radiology images based on their semantic similarity.
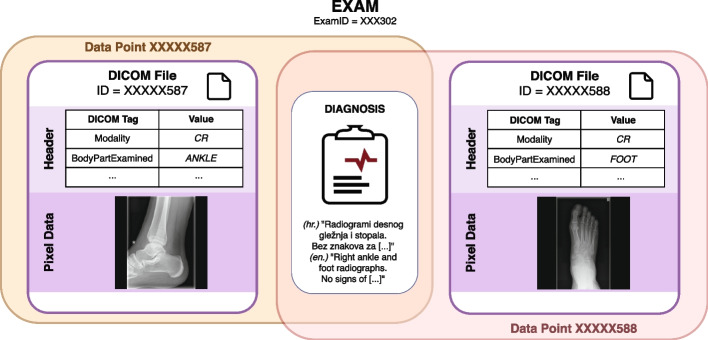
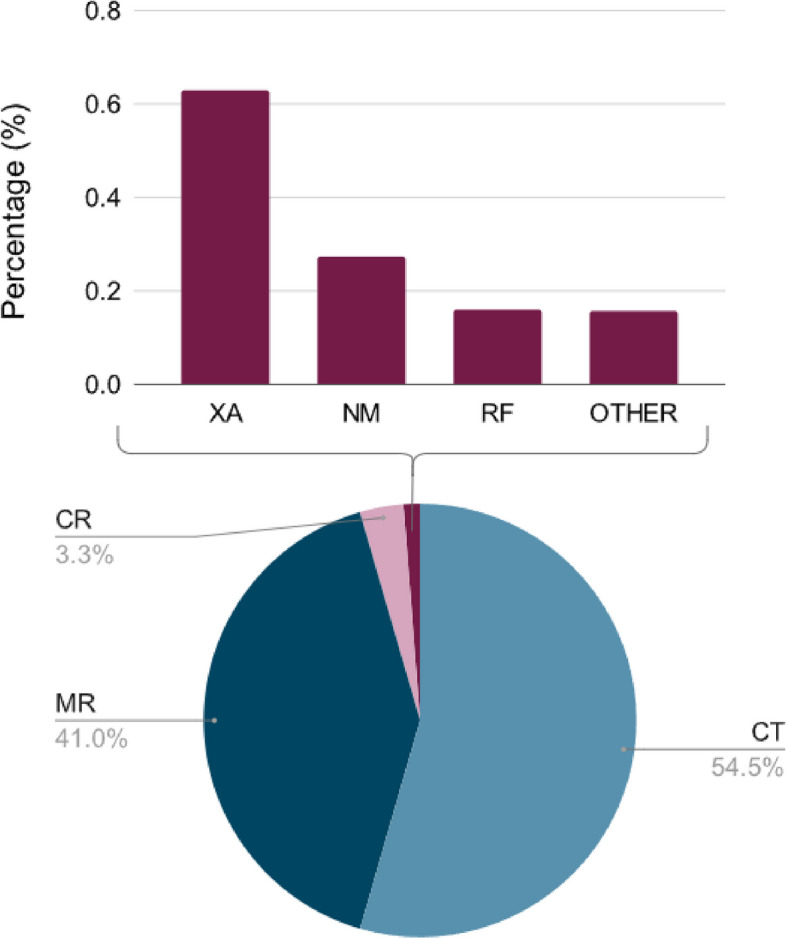
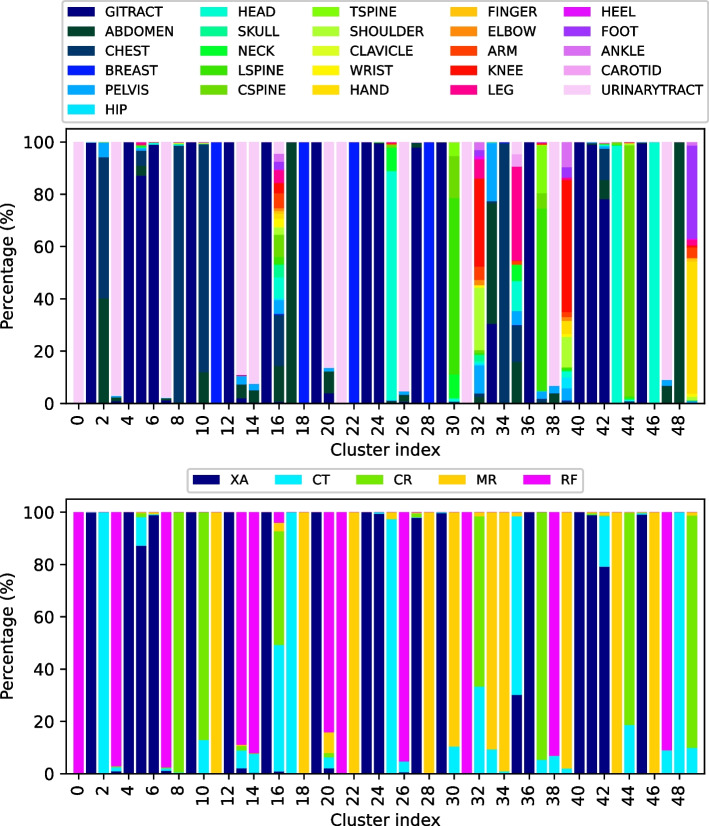
Results: An automated, unsupervised approach is used to create a large annotated dataset of medical radiology images originating from the Clinical Hospital Centre Rijeka, Croatia. The pipeline is built by data-mining three different types of medical data: images, DICOM metadata and narrative diagnoses. The optimal feature extractors are then integrated into a multimodal representation, which is then clustered to create an automated pipeline for labelling a precursor dataset of 1,337,926 medical images into 50 clusters of visually similar images. The quality of the clusters is assessed by examining their homogeneity and mutual information, taking into account the anatomical region and modality representation.
Conclusions: The results indicate that fusing the embeddings of all three data sources together provides the best results for the task of unsupervised clustering of large-scale medical data and leads to the most concise clusters. Hence, this work marks the initial step towards building a much larger and more fine-grained annotated dataset of medical radiology images.
期刊介绍:
BioData Mining is an open access, open peer-reviewed journal encompassing research on all aspects of data mining applied to high-dimensional biological and biomedical data, focusing on computational aspects of knowledge discovery from large-scale genetic, transcriptomic, genomic, proteomic, and metabolomic data.
Topical areas include, but are not limited to:
-Development, evaluation, and application of novel data mining and machine learning algorithms.
-Adaptation, evaluation, and application of traditional data mining and machine learning algorithms.
-Open-source software for the application of data mining and machine learning algorithms.
-Design, development and integration of databases, software and web services for the storage, management, retrieval, and analysis of data from large scale studies.
-Pre-processing, post-processing, modeling, and interpretation of data mining and machine learning results for biological interpretation and knowledge discovery.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
