Bo Han, Yuheng Li, Yixuan Shen, Yi Ren, Feilin Han
{"title":"Dance2MIDI: Dance-driven multi-instrument music generation","authors":"Bo Han, Yuheng Li, Yixuan Shen, Yi Ren, Feilin Han","doi":"10.1007/s41095-024-0417-1","DOIUrl":null,"url":null,"abstract":"<p>Dance-driven music generation aims to generate musical pieces conditioned on dance videos. Previous works focus on monophonic or raw audio generation, while the multi-instrument scenario is under-explored. The challenges associated with dance-driven multi-instrument music (MIDI) generation are twofold: (i) lack of a publicly available multi-instrument MIDI and video paired dataset and (ii) the weak correlation between music and video. To tackle these challenges, we have built the first multi-instrument MIDI and dance paired dataset (D2MIDI). Based on this dataset, we introduce a multi-instrument MIDI generation framework (Dance2MIDI) conditioned on dance video. Firstly, to capture the relationship between dance and music, we employ a graph convolutional network to encode the dance motion. This allows us to extract features related to dance movement and dance style. Secondly, to generate a harmonious rhythm, we utilize a transformer model to decode the drum track sequence, leveraging a cross-attention mechanism. Thirdly, we model the task of generating the remaining tracks based on the drum track as a sequence understanding and completion task. A BERT-like model is employed to comprehend the context of the entire music piece through self-supervised learning. We evaluate the music generated by our framework trained on the D2MIDI dataset and demonstrate that our method achieves state-of-the-art performance.</p>","PeriodicalId":37301,"journal":{"name":"Computational Visual Media","volume":"38 1","pages":""},"PeriodicalIF":18.3000,"publicationDate":"2024-07-24","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computational Visual Media","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s41095-024-0417-1","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
引用次数: 0
Abstract
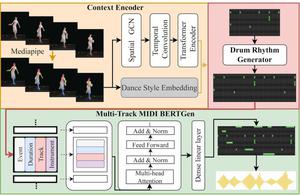
Dance-driven music generation aims to generate musical pieces conditioned on dance videos. Previous works focus on monophonic or raw audio generation, while the multi-instrument scenario is under-explored. The challenges associated with dance-driven multi-instrument music (MIDI) generation are twofold: (i) lack of a publicly available multi-instrument MIDI and video paired dataset and (ii) the weak correlation between music and video. To tackle these challenges, we have built the first multi-instrument MIDI and dance paired dataset (D2MIDI). Based on this dataset, we introduce a multi-instrument MIDI generation framework (Dance2MIDI) conditioned on dance video. Firstly, to capture the relationship between dance and music, we employ a graph convolutional network to encode the dance motion. This allows us to extract features related to dance movement and dance style. Secondly, to generate a harmonious rhythm, we utilize a transformer model to decode the drum track sequence, leveraging a cross-attention mechanism. Thirdly, we model the task of generating the remaining tracks based on the drum track as a sequence understanding and completion task. A BERT-like model is employed to comprehend the context of the entire music piece through self-supervised learning. We evaluate the music generated by our framework trained on the D2MIDI dataset and demonstrate that our method achieves state-of-the-art performance.
期刊介绍:
Computational Visual Media is a peer-reviewed open access journal. It publishes original high-quality research papers and significant review articles on novel ideas, methods, and systems relevant to visual media.
Computational Visual Media publishes articles that focus on, but are not limited to, the following areas:
• Editing and composition of visual media
• Geometric computing for images and video
• Geometry modeling and processing
• Machine learning for visual media
• Physically based animation
• Realistic rendering
• Recognition and understanding of visual media
• Visual computing for robotics
• Visualization and visual analytics
Other interdisciplinary research into visual media that combines aspects of computer graphics, computer vision, image and video processing, geometric computing, and machine learning is also within the journal''s scope.
This is an open access journal, published quarterly by Tsinghua University Press and Springer. The open access fees (article-processing charges) are fully sponsored by Tsinghua University, China. Authors can publish in the journal without any additional charges.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
