Majid Afshar , Yanjun Gao , Deepak Gupta , Emma Croxford , Dina Demner-Fushman
{"title":"On the role of the UMLS in supporting diagnosis generation proposed by Large Language Models","authors":"Majid Afshar , Yanjun Gao , Deepak Gupta , Emma Croxford , Dina Demner-Fushman","doi":"10.1016/j.jbi.2024.104707","DOIUrl":null,"url":null,"abstract":"<div><h3>Objective:</h3><p>Traditional knowledge-based and machine learning diagnostic decision support systems have benefited from integrating the medical domain knowledge encoded in the Unified Medical Language System (UMLS). The emergence of Large Language Models (LLMs) to supplant traditional systems poses questions of the quality and extent of the medical knowledge in the models’ internal knowledge representations and the need for external knowledge sources. The objective of this study is three-fold: to probe the diagnosis-related medical knowledge of popular LLMs, to examine the benefit of providing the UMLS knowledge to LLMs (grounding the diagnosis predictions), and to evaluate the correlations between human judgments and the UMLS-based metrics for generations by LLMs.</p></div><div><h3>Methods:</h3><p>We evaluated diagnoses generated by LLMs from consumer health questions and daily care notes in the electronic health records using the ConsumerQA and Problem Summarization datasets. Probing LLMs for the UMLS knowledge was performed by prompting the LLM to complete the diagnosis-related UMLS knowledge paths. Grounding the predictions was examined in an approach that integrated the UMLS graph paths and clinical notes in prompting the LLMs. The results were compared to prompting without the UMLS paths. The final experiments examined the alignment of different evaluation metrics, UMLS-based and non-UMLS, with human expert evaluation.</p></div><div><h3>Results:</h3><p>In probing the UMLS knowledge, GPT-3.5 significantly outperformed Llama2 and a simple baseline yielding an F1 score of 10.9% in completing one-hop UMLS paths for a given concept. Grounding diagnosis predictions with the UMLS paths improved the results for both models on both tasks, with the highest improvement (4%) in SapBERT score. There was a weak correlation between the widely used evaluation metrics (ROUGE and SapBERT) and human judgments.</p></div><div><h3>Conclusion:</h3><p>We found that while popular LLMs contain some medical knowledge in their internal representations, augmentation with the UMLS knowledge provides performance gains around diagnosis generation. The UMLS needs to be tailored for the task to improve the LLMs predictions. Finding evaluation metrics that are aligned with human judgments better than the traditional ROUGE and BERT-based scores remains an open research question.</p></div>","PeriodicalId":15263,"journal":{"name":"Journal of Biomedical Informatics","volume":"157 ","pages":"Article 104707"},"PeriodicalIF":4.5000,"publicationDate":"2024-09-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Biomedical Informatics","FirstCategoryId":"3","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1532046424001254","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/8/13 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
引用次数: 0
Abstract
Objective:
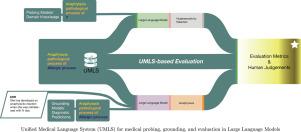
Traditional knowledge-based and machine learning diagnostic decision support systems have benefited from integrating the medical domain knowledge encoded in the Unified Medical Language System (UMLS). The emergence of Large Language Models (LLMs) to supplant traditional systems poses questions of the quality and extent of the medical knowledge in the models’ internal knowledge representations and the need for external knowledge sources. The objective of this study is three-fold: to probe the diagnosis-related medical knowledge of popular LLMs, to examine the benefit of providing the UMLS knowledge to LLMs (grounding the diagnosis predictions), and to evaluate the correlations between human judgments and the UMLS-based metrics for generations by LLMs.
Methods:
We evaluated diagnoses generated by LLMs from consumer health questions and daily care notes in the electronic health records using the ConsumerQA and Problem Summarization datasets. Probing LLMs for the UMLS knowledge was performed by prompting the LLM to complete the diagnosis-related UMLS knowledge paths. Grounding the predictions was examined in an approach that integrated the UMLS graph paths and clinical notes in prompting the LLMs. The results were compared to prompting without the UMLS paths. The final experiments examined the alignment of different evaluation metrics, UMLS-based and non-UMLS, with human expert evaluation.
Results:
In probing the UMLS knowledge, GPT-3.5 significantly outperformed Llama2 and a simple baseline yielding an F1 score of 10.9% in completing one-hop UMLS paths for a given concept. Grounding diagnosis predictions with the UMLS paths improved the results for both models on both tasks, with the highest improvement (4%) in SapBERT score. There was a weak correlation between the widely used evaluation metrics (ROUGE and SapBERT) and human judgments.
Conclusion:
We found that while popular LLMs contain some medical knowledge in their internal representations, augmentation with the UMLS knowledge provides performance gains around diagnosis generation. The UMLS needs to be tailored for the task to improve the LLMs predictions. Finding evaluation metrics that are aligned with human judgments better than the traditional ROUGE and BERT-based scores remains an open research question.
期刊介绍:
The Journal of Biomedical Informatics reflects a commitment to high-quality original research papers, reviews, and commentaries in the area of biomedical informatics methodology. Although we publish articles motivated by applications in the biomedical sciences (for example, clinical medicine, health care, population health, and translational bioinformatics), the journal emphasizes reports of new methodologies and techniques that have general applicability and that form the basis for the evolving science of biomedical informatics. Articles on medical devices; evaluations of implemented systems (including clinical trials of information technologies); or papers that provide insight into a biological process, a specific disease, or treatment options would generally be more suitable for publication in other venues. Papers on applications of signal processing and image analysis are often more suitable for biomedical engineering journals or other informatics journals, although we do publish papers that emphasize the information management and knowledge representation/modeling issues that arise in the storage and use of biological signals and images. System descriptions are welcome if they illustrate and substantiate the underlying methodology that is the principal focus of the report and an effort is made to address the generalizability and/or range of application of that methodology. Note also that, given the international nature of JBI, papers that deal with specific languages other than English, or with country-specific health systems or approaches, are acceptable for JBI only if they offer generalizable lessons that are relevant to the broad JBI readership, regardless of their country, language, culture, or health system.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
