Dongjin Huang , Nan Wang , Xinghan Huang , Jiantao Qu , Shiyu Zhang
{"title":"Mesh-controllable multi-level-of-detail text-to-3D generation","authors":"Dongjin Huang , Nan Wang , Xinghan Huang , Jiantao Qu , Shiyu Zhang","doi":"10.1016/j.cag.2024.104039","DOIUrl":null,"url":null,"abstract":"<div><p>Text-to-3D generation is a challenging but significant task and has gained widespread attention. Its capability to rapidly generate 3D digital assets holds huge potential application value in fields such as film, video games, and virtual reality. However, current methods often face several drawbacks, including long generation times, difficulties with the multi-face Janus problem, and issues like chaotic topology and redundant structures during mesh extraction. Additionally, the lack of control over the generated results limits their utility in downstream applications. To address these problems, we propose a novel text-to-3D framework capable of generating meshes with high fidelity and controllability. Our approach can efficiently produce meshes and textures that match the text description and the desired level of detail (LOD) by specifying input text and LOD preferences. This framework consists of two stages. In the coarse stage, 3D Gaussians are employed to accelerate generation speed, and weighted positive and negative prompts from various observation perspectives are used to address the multi-face Janus problem in the generated results. In the refinement stage, mesh vertices and faces are iteratively refined to enhance surface quality and output meshes and textures that meet specified LOD requirements. Compared to the state-of-the-art text-to-3D methods, extensive experiments demonstrate that the proposed method performs better in solving the multi-face Janus problem, enabling the rapid generation of 3D meshes with enhanced prompt adherence. Furthermore, the proposed framework can generate meshes with enhanced topology, offering controllable vertices and faces with textures featuring UV adaptation to achieve multi-level-of-detail(LODs) outputs. Specifically, the proposed method can preserve the output’s relevance to input texts during simplification, making it better suited for mesh editing and rendering efficiency. User studies also indicate that our framework receives higher evaluations compared to other methods.</p></div>","PeriodicalId":50628,"journal":{"name":"Computers & Graphics-Uk","volume":"123 ","pages":"Article 104039"},"PeriodicalIF":2.8000,"publicationDate":"2024-08-10","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computers & Graphics-Uk","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0097849324001742","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
引用次数: 0
Abstract
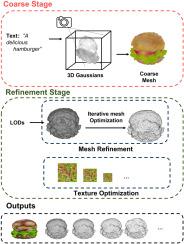
Text-to-3D generation is a challenging but significant task and has gained widespread attention. Its capability to rapidly generate 3D digital assets holds huge potential application value in fields such as film, video games, and virtual reality. However, current methods often face several drawbacks, including long generation times, difficulties with the multi-face Janus problem, and issues like chaotic topology and redundant structures during mesh extraction. Additionally, the lack of control over the generated results limits their utility in downstream applications. To address these problems, we propose a novel text-to-3D framework capable of generating meshes with high fidelity and controllability. Our approach can efficiently produce meshes and textures that match the text description and the desired level of detail (LOD) by specifying input text and LOD preferences. This framework consists of two stages. In the coarse stage, 3D Gaussians are employed to accelerate generation speed, and weighted positive and negative prompts from various observation perspectives are used to address the multi-face Janus problem in the generated results. In the refinement stage, mesh vertices and faces are iteratively refined to enhance surface quality and output meshes and textures that meet specified LOD requirements. Compared to the state-of-the-art text-to-3D methods, extensive experiments demonstrate that the proposed method performs better in solving the multi-face Janus problem, enabling the rapid generation of 3D meshes with enhanced prompt adherence. Furthermore, the proposed framework can generate meshes with enhanced topology, offering controllable vertices and faces with textures featuring UV adaptation to achieve multi-level-of-detail(LODs) outputs. Specifically, the proposed method can preserve the output’s relevance to input texts during simplification, making it better suited for mesh editing and rendering efficiency. User studies also indicate that our framework receives higher evaluations compared to other methods.
期刊介绍:
Computers & Graphics is dedicated to disseminate information on research and applications of computer graphics (CG) techniques. The journal encourages articles on:
1. Research and applications of interactive computer graphics. We are particularly interested in novel interaction techniques and applications of CG to problem domains.
2. State-of-the-art papers on late-breaking, cutting-edge research on CG.
3. Information on innovative uses of graphics principles and technologies.
4. Tutorial papers on both teaching CG principles and innovative uses of CG in education.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
