{"title":"Machine learning-based reproducible prediction of type 2 diabetes subtypes.","authors":"Hayato Tanabe, Masahiro Sato, Akimitsu Miyake, Yoshinori Shimajiri, Takafumi Ojima, Akira Narita, Haruka Saito, Kenichi Tanaka, Hiroaki Masuzaki, Junichiro J Kazama, Hideki Katagiri, Gen Tamiya, Eiryo Kawakami, Michio Shimabukuro","doi":"10.1007/s00125-024-06248-8","DOIUrl":null,"url":null,"abstract":"<p><strong>Aims/hypothesis: </strong>Clustering-based subclassification of type 2 diabetes, which reflects pathophysiology and genetic predisposition, is a promising approach for providing personalised and effective therapeutic strategies. Ahlqvist's classification is currently the most vigorously validated method because of its superior ability to predict diabetes complications but it does not have strong consistency over time and requires HOMA2 indices, which are not routinely available in clinical practice and standard cohort studies. We developed a machine learning (ML) model to classify individuals with type 2 diabetes into Ahlqvist's subtypes consistently over time.</p><p><strong>Methods: </strong>Cohort 1 dataset comprised 619 Japanese individuals with type 2 diabetes who were divided into training and test sets for ML models in a 7:3 ratio. Cohort 2 dataset, comprising 597 individuals with type 2 diabetes, was used for external validation. Participants were pre-labelled (T2D<sub>kmeans</sub>) by unsupervised k-means clustering based on Ahlqvist's variables (age at diagnosis, BMI, HbA<sub>1c</sub>, HOMA2-B and HOMA2-IR) to four subtypes: severe insulin-deficient diabetes (SIDD), severe insulin-resistant diabetes (SIRD), mild obesity-related diabetes (MOD) and mild age-related diabetes (MARD). We adopted 15 variables for a multiclass classification random forest (RF) algorithm to predict type 2 diabetes subtypes (T2D<sub>RF15</sub>). The proximity matrix computed by RF was visualised using a uniform manifold approximation and projection. Finally, we used a putative subset with missing insulin-related variables to test the predictive performance of the validation cohort, consistency of subtypes over time and prediction ability of diabetes complications.</p><p><strong>Results: </strong>T2D<sub>RF15</sub> demonstrated a 94% accuracy for predicting T2D<sub>kmeans</sub> type 2 diabetes subtypes (AUCs ≥0.99 and F1 score [an indicator calculated by harmonic mean from precision and recall] ≥0.9) and retained the predictive performance in the external validation cohort (86.3%). T2D<sub>RF15</sub> showed an accuracy of 82.9% for detecting T2D<sub>kmeans</sub>, also in a putative subset with missing insulin-related variables, when used with an imputation algorithm. In Kaplan-Meier analysis, the diabetes clusters of T2D<sub>RF15</sub> demonstrated distinct accumulation risks of diabetic retinopathy in SIDD and that of chronic kidney disease in SIRD during a median observation period of 11.6 (4.5-18.3) years, similarly to the subtypes using T2D<sub>kmeans</sub>. The predictive accuracy was improved after excluding individuals with low predictive probability, who were categorised as an 'undecidable' cluster. T2D<sub>RF15</sub>, after excluding undecidable individuals, showed higher consistency (100% for SIDD, 68.6% for SIRD, 94.4% for MOD and 97.9% for MARD) than T2D<sub>kmeans</sub>.</p><p><strong>Conclusions/interpretation: </strong>The new ML model for predicting Ahlqvist's subtypes of type 2 diabetes has great potential for application in clinical practice and cohort studies because it can classify individuals with missing HOMA2 indices and predict glycaemic control, diabetic complications and treatment outcomes with long-term consistency by using readily available variables. Future studies are needed to assess whether our approach is applicable to research and/or clinical practice in multiethnic populations.</p>","PeriodicalId":11164,"journal":{"name":"Diabetologia","volume":" ","pages":"2446-2458"},"PeriodicalIF":10.2000,"publicationDate":"2024-11-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11519166/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Diabetologia","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1007/s00125-024-06248-8","RegionNum":1,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/8/21 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"ENDOCRINOLOGY & METABOLISM","Score":null,"Total":0}
引用次数: 0
Abstract
Aims/hypothesis: Clustering-based subclassification of type 2 diabetes, which reflects pathophysiology and genetic predisposition, is a promising approach for providing personalised and effective therapeutic strategies. Ahlqvist's classification is currently the most vigorously validated method because of its superior ability to predict diabetes complications but it does not have strong consistency over time and requires HOMA2 indices, which are not routinely available in clinical practice and standard cohort studies. We developed a machine learning (ML) model to classify individuals with type 2 diabetes into Ahlqvist's subtypes consistently over time.
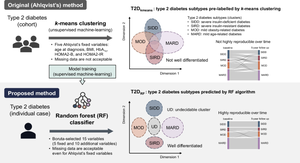
Methods: Cohort 1 dataset comprised 619 Japanese individuals with type 2 diabetes who were divided into training and test sets for ML models in a 7:3 ratio. Cohort 2 dataset, comprising 597 individuals with type 2 diabetes, was used for external validation. Participants were pre-labelled (T2Dkmeans) by unsupervised k-means clustering based on Ahlqvist's variables (age at diagnosis, BMI, HbA1c, HOMA2-B and HOMA2-IR) to four subtypes: severe insulin-deficient diabetes (SIDD), severe insulin-resistant diabetes (SIRD), mild obesity-related diabetes (MOD) and mild age-related diabetes (MARD). We adopted 15 variables for a multiclass classification random forest (RF) algorithm to predict type 2 diabetes subtypes (T2DRF15). The proximity matrix computed by RF was visualised using a uniform manifold approximation and projection. Finally, we used a putative subset with missing insulin-related variables to test the predictive performance of the validation cohort, consistency of subtypes over time and prediction ability of diabetes complications.
Results: T2DRF15 demonstrated a 94% accuracy for predicting T2Dkmeans type 2 diabetes subtypes (AUCs ≥0.99 and F1 score [an indicator calculated by harmonic mean from precision and recall] ≥0.9) and retained the predictive performance in the external validation cohort (86.3%). T2DRF15 showed an accuracy of 82.9% for detecting T2Dkmeans, also in a putative subset with missing insulin-related variables, when used with an imputation algorithm. In Kaplan-Meier analysis, the diabetes clusters of T2DRF15 demonstrated distinct accumulation risks of diabetic retinopathy in SIDD and that of chronic kidney disease in SIRD during a median observation period of 11.6 (4.5-18.3) years, similarly to the subtypes using T2Dkmeans. The predictive accuracy was improved after excluding individuals with low predictive probability, who were categorised as an 'undecidable' cluster. T2DRF15, after excluding undecidable individuals, showed higher consistency (100% for SIDD, 68.6% for SIRD, 94.4% for MOD and 97.9% for MARD) than T2Dkmeans.
Conclusions/interpretation: The new ML model for predicting Ahlqvist's subtypes of type 2 diabetes has great potential for application in clinical practice and cohort studies because it can classify individuals with missing HOMA2 indices and predict glycaemic control, diabetic complications and treatment outcomes with long-term consistency by using readily available variables. Future studies are needed to assess whether our approach is applicable to research and/or clinical practice in multiethnic populations.
期刊介绍:
Diabetologia, the authoritative journal dedicated to diabetes research, holds high visibility through society membership, libraries, and social media. As the official journal of the European Association for the Study of Diabetes, it is ranked in the top quartile of the 2019 JCR Impact Factors in the Endocrinology & Metabolism category. The journal boasts dedicated and expert editorial teams committed to supporting authors throughout the peer review process.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
