{"title":"Linear-size suffix tries and linear-size CDAWGs simplified and improved","authors":"Shunsuke Inenaga","doi":"10.1007/s00236-024-00465-9","DOIUrl":null,"url":null,"abstract":"<div><p>The <i>linear-size suffix tries</i> (<i>LSTries</i>) (Crochemore et al. in Theor Comput Sci 638:171–178, 2016) are a version of suffix trees in which the edge labels are single characters, yet are able to perform pattern matching queries in optimal time. Instead of explicitly storing the input text, LSTries have some extra non-branching internal nodes called <i>type-2</i> nodes. The extended techniques are then used in the <i>linear-size compact directed acyclic word graphs</i> (<i>LCDAWGs</i>) (Takagi et al., in: SPIRE 2017, pp. 304–316, 2017), which can be stored with <span>\\(O(\\textsf{el}(T)+\\textsf{er}(T))\\)</span> space (i.e. without the text), where <span>\\(\\textsf{el}(T)\\)</span> and <span>\\(\\textsf{er}(T)\\)</span> are the numbers of left- and right-extensions of the maximal repeats in the input text string <i>T</i>, respectively. In this paper, we present simpler alternatives to the aforementioned indexing structures, called the <i>simplified LSTries</i> (<i>simLSTries</i>) and the <i>simplified LCDAWGs</i> (<i>simLCDAWGs</i>), in which most of the type-2 nodes are removed. In particular, our simLCDAWGs require only <span>\\(O(\\textsf{er}(T))\\)</span> space and work in a weaker model of computation (i.e. the pointer machine model). This contrasts the <span>\\(O(\\textsf{er}(T))\\)</span>-space CDAWG representation of Belazzougui and Cunial (in: Proceedings of the 24th international symposium on string processing and information retrieval, pp. 161–175, 2017), which works on the word RAM model.</p></div>","PeriodicalId":7189,"journal":{"name":"Acta Informatica","volume":"61 4","pages":"445 - 468"},"PeriodicalIF":0.5000,"publicationDate":"2024-08-23","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Acta Informatica","FirstCategoryId":"94","ListUrlMain":"https://link.springer.com/article/10.1007/s00236-024-00465-9","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q4","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
引用次数: 0
Abstract
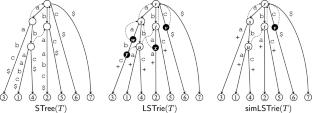
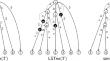
The linear-size suffix tries (LSTries) (Crochemore et al. in Theor Comput Sci 638:171–178, 2016) are a version of suffix trees in which the edge labels are single characters, yet are able to perform pattern matching queries in optimal time. Instead of explicitly storing the input text, LSTries have some extra non-branching internal nodes called type-2 nodes. The extended techniques are then used in the linear-size compact directed acyclic word graphs (LCDAWGs) (Takagi et al., in: SPIRE 2017, pp. 304–316, 2017), which can be stored with \(O(\textsf{el}(T)+\textsf{er}(T))\) space (i.e. without the text), where \(\textsf{el}(T)\) and \(\textsf{er}(T)\) are the numbers of left- and right-extensions of the maximal repeats in the input text string T, respectively. In this paper, we present simpler alternatives to the aforementioned indexing structures, called the simplified LSTries (simLSTries) and the simplified LCDAWGs (simLCDAWGs), in which most of the type-2 nodes are removed. In particular, our simLCDAWGs require only \(O(\textsf{er}(T))\) space and work in a weaker model of computation (i.e. the pointer machine model). This contrasts the \(O(\textsf{er}(T))\)-space CDAWG representation of Belazzougui and Cunial (in: Proceedings of the 24th international symposium on string processing and information retrieval, pp. 161–175, 2017), which works on the word RAM model.
期刊介绍:
Acta Informatica provides international dissemination of articles on formal methods for the design and analysis of programs, computing systems and information structures, as well as related fields of Theoretical Computer Science such as Automata Theory, Logic in Computer Science, and Algorithmics.
Topics of interest include:
• semantics of programming languages
• models and modeling languages for concurrent, distributed, reactive and mobile systems
• models and modeling languages for timed, hybrid and probabilistic systems
• specification, program analysis and verification
• model checking and theorem proving
• modal, temporal, first- and higher-order logics, and their variants
• constraint logic, SAT/SMT-solving techniques
• theoretical aspects of databases, semi-structured data and finite model theory
• theoretical aspects of artificial intelligence, knowledge representation, description logic
• automata theory, formal languages, term and graph rewriting
• game-based models, synthesis
• type theory, typed calculi
• algebraic, coalgebraic and categorical methods
• formal aspects of performance, dependability and reliability analysis
• foundations of information and network security
• parallel, distributed and randomized algorithms
• design and analysis of algorithms
• foundations of network and communication protocols.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
