Syauki Aulia Thamrin, Eva E. Chen, Arbee L. P. Chen
{"title":"Detecting bipolar disorder on social media by post grouping and interpretable deep learning","authors":"Syauki Aulia Thamrin, Eva E. Chen, Arbee L. P. Chen","doi":"10.1007/s10844-024-00884-7","DOIUrl":null,"url":null,"abstract":"<p>Bipolar disorder is a disorder in which a person expresses manic and depressed emotions repeatedly. Diagnosing bipolar disorder accurately can be difficult because other mood disorders or even regular mood changes may have similar symptoms. Therefore, psychiatrists need to spend a long time observing and interviewing clients to make the diagnosis. Recent studies have trained machine learning models for detecting bipolar disorder on social media. However, most of these studies focused on increasing the accuracy of the model without explaining the classification results. Although the posts of a bipolar disorder user can be observed manually, doing so is not practical since a user can have many posts which may not depict any signs of bipolar disorder. Without any explanations, the trustworthiness of the model decreases. We propose a deep learning model that not only detects and classifies bipolar disorder users but also explains how the model generates the classification results. The posts are first grouped using Latent Dirichlet Allocation, a method commonly used to classify the topic of a text. These groups are then input into the model, and attention mechanisms are utilized to determine which groups have more attention weights and are considered more heavily. Finally, an explanation of the classification results is obtained by visualizing the attention weights. Several case studies are presented to demonstrate the explanations generated through our proposed model. Our model is also compared to other models, achieving the best performance with an F1-Score of 0.92.</p>","PeriodicalId":56119,"journal":{"name":"Journal of Intelligent Information Systems","volume":"81 1","pages":""},"PeriodicalIF":3.4000,"publicationDate":"2024-09-11","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Intelligent Information Systems","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10844-024-00884-7","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
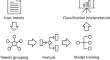
Bipolar disorder is a disorder in which a person expresses manic and depressed emotions repeatedly. Diagnosing bipolar disorder accurately can be difficult because other mood disorders or even regular mood changes may have similar symptoms. Therefore, psychiatrists need to spend a long time observing and interviewing clients to make the diagnosis. Recent studies have trained machine learning models for detecting bipolar disorder on social media. However, most of these studies focused on increasing the accuracy of the model without explaining the classification results. Although the posts of a bipolar disorder user can be observed manually, doing so is not practical since a user can have many posts which may not depict any signs of bipolar disorder. Without any explanations, the trustworthiness of the model decreases. We propose a deep learning model that not only detects and classifies bipolar disorder users but also explains how the model generates the classification results. The posts are first grouped using Latent Dirichlet Allocation, a method commonly used to classify the topic of a text. These groups are then input into the model, and attention mechanisms are utilized to determine which groups have more attention weights and are considered more heavily. Finally, an explanation of the classification results is obtained by visualizing the attention weights. Several case studies are presented to demonstrate the explanations generated through our proposed model. Our model is also compared to other models, achieving the best performance with an F1-Score of 0.92.
期刊介绍:
The mission of the Journal of Intelligent Information Systems: Integrating Artifical Intelligence and Database Technologies is to foster and present research and development results focused on the integration of artificial intelligence and database technologies to create next generation information systems - Intelligent Information Systems.
These new information systems embody knowledge that allows them to exhibit intelligent behavior, cooperate with users and other systems in problem solving, discovery, access, retrieval and manipulation of a wide variety of multimedia data and knowledge, and reason under uncertainty. Increasingly, knowledge-directed inference processes are being used to:
discover knowledge from large data collections,
provide cooperative support to users in complex query formulation and refinement,
access, retrieve, store and manage large collections of multimedia data and knowledge,
integrate information from multiple heterogeneous data and knowledge sources, and
reason about information under uncertain conditions.
Multimedia and hypermedia information systems now operate on a global scale over the Internet, and new tools and techniques are needed to manage these dynamic and evolving information spaces.
The Journal of Intelligent Information Systems provides a forum wherein academics, researchers and practitioners may publish high-quality, original and state-of-the-art papers describing theoretical aspects, systems architectures, analysis and design tools and techniques, and implementation experiences in intelligent information systems. The categories of papers published by JIIS include: research papers, invited papters, meetings, workshop and conference annoucements and reports, survey and tutorial articles, and book reviews. Short articles describing open problems or their solutions are also welcome.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
